この記事は、AMD 社のウェブサイトで公開されている「ZenDNN 5.2: Accelerating vLLM V1 Engine and Recommender Systems Inference on AMD EPYC™ CPUs」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
2026年3月13日

Shailen Sobhee
AI グループ担当 シニア・プロダクト・マーケティング・マネージャー
Advanced Micro Devices, Inc.
AMD は明確なメッセージを打ち出しています。AI 推論の未来は、柔軟で効率的であり、すでに導入済みのサーバーに搭載されている CPU によってますます支えられていく、ということです。実際、人工知能の世界では、GPU が主役となってきました。これには十分な理由があり、GPU が今後も不可欠な存在であり続けることに変わりはありません。膨大な並列処理能力を持つ GPU は、高スループットな LLM 推論といった重負荷ワークロードにおいて、依然として事実上の標準です。しかし、CPU はもはや傍観者ではありません。LLM 推論において、高性能エンジンとして活用される存在へと進化しています。
ZenDNN 5.2 の最新リリースにより、AMD は AI 時代における x86 アーキテクチャの可能性に対する常識を覆しつつあります。これは単なる段階的な性能向上ではありません。従来バージョン比で最大 200% の性能向上を実現し、AMD EPYC™ プロセッサー上での AI ワークロードの効率を実質的に倍増させています。
なぜ重要なのか ― AI 活用の広がり
これは単なる数値上の性能向上にとどまりません。新たなコンピューティングの可能性を切り拓くものです。
- エージェント型 AI:
自律型エージェントを効果的に実行するには、応答遅延が少なく、信頼性の高い計算基盤が求められます。vLLM との統合最適化や INT4 量子化により、高度な LLM エージェントを CPU ベースのインフラで、容易に導入・実行できるようになります。 - オフラインおよびエッジ環境での活用:
プライバシーやネットワーク接続が常に確保されているとは限りません。Weight-Only Quantization (WOQ) の限界を押し広げることで、AMD は大規模モデルを専用のデータ センター GPU に依存することなく、ローカル環境で効率的に実行できるようにします。 - 既存ハードウェアでの AI 推論の高速化:
一般的なサーバー構成では、CPU は依然としてシステムの中核を担っています。こうした CPU を AI に活用することで、総所有コスト (TCO) の削減につながります。
内部構造で何が変わったのか
ZenDNN 5.2 では、アーキテクチャに大きな変更が加えられました。AMD は従来のライブラリから新しい ZenDNNL へ移行し、Low Overhead API (LOA) を活用することで、MatMul や Softmax といった演算カーネルを効率的に処理できるようになりました。
主なアップデートのポイント
- vLLM V1 とのシームレスな統合:
新しい vLLM-ZenTorch プラグインにより、コード変更なしで高速化が可能となり、高スループットな推論をより手軽に実現できます。 - 量子化のサポート:
LLM 向けの実験的な INT4 対応に加え、レコメンダー システム (DLRM-v2) 向けに特化した UINT4/W8A8 量子化をサポートしています。 - BFloat16 およびグラフ最適化:
EPYC™ プロセッサー向けに最適化されたカーネルの強化と高度なパターン認識により、CPU の性能を最大限に引き出し、AI パフォーマンスを向上させます。 - 最新のソフトウェア スタック:
TensorFlow 2.20、PyTorch 2.10.0、Python 3.13 をフルサポートしています。 - Llama.cpp 向け ZenDNN バックエンド:
ZenDNN 5.2 の開発過程で実装されたこの統合により、Llama.cpp ユーザーは ZenDNN の低レイテンシなカーネルを活用し、AMD EPYC™ プロセッサー上でより高い実行性能を実現できます。
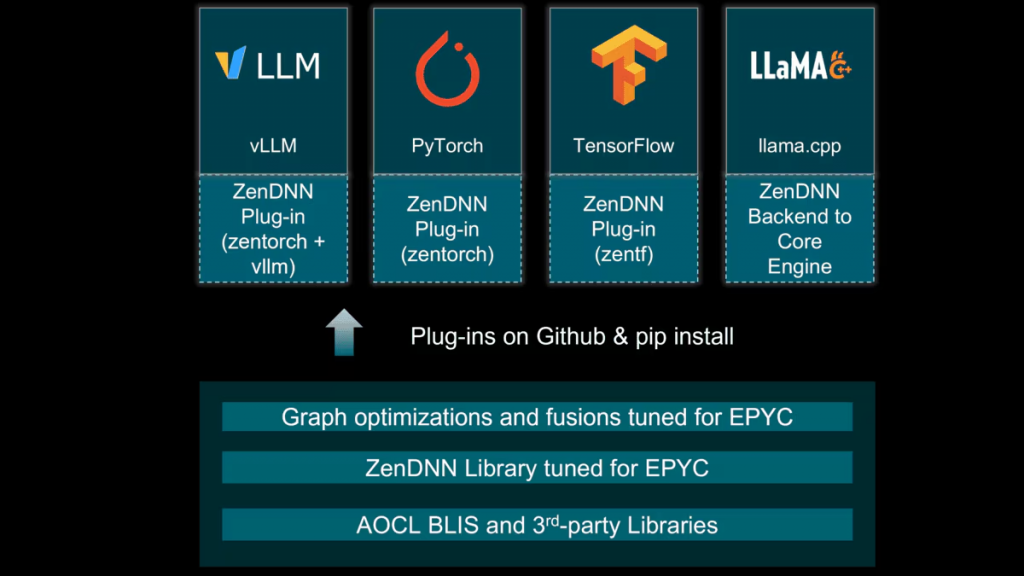
図1:ZenDNN フレームワークの全体像
AMD ZenDNN による vLLM V1 エンジンの高速化
CPU を活用した LLM 推論は、これまで一部用途に限られていた手法から、実運用ワークロードにおける高度でコスト効率の高い選択肢へと急速に進化しています。ZenDNN 5.2 のリリースに伴い、プラグインは最先端のvLLM V1 エンジンに対応するよう強化されました。開発チームは「コード変更不要」という方針に注力し、vLLM 0.12.0 から 0.15.1 までのバージョンにおいて、真のプラグ アンド プレイ体験を提供すると同時に、内部での大幅な高速化を実現しています。当社の検証では、特定条件に偏らないモデル (non-cherry-picked models) を用いた場合でも、vLLM と ZenTorch の組み合わせにより、標準の vLLM を CPU 環境で実行した場合と比較して、最大239% の性能向上を達成しました。
ソフトウェア スタックの改善に加え、ハードウェアによるデータ処理の最適化によって、さらなる性能向上も実現しています。numactl を用いて複数の vLLM インスタンスを展開し、各インスタンスのメモリアクセスをインターリーブ化することで、DRAM のメモリ帯域を最大限に活用しています。この手法により、CPU は単に高速に処理するだけでなく、より効率的にデータを受け取ることが可能になり、サーバー全体のデコード処理スループットが大幅に向上します。
実装 ― スループットを最大化する方法
効率的なスケーリング:
最新の AMD EPYC™ プロセッサーは非常に高いコア密度を備えていますが、単一の大規模な vLLM インスタンスをソケット内の 128 コアすべてで実行しても、必ずしも性能が最大化されるわけではありません。実際に、0~127 の全コアを使用して標準の vLLM を検証したところ、広範な計算リソースの管理やメモリ競合の影響により、期待に反して性能が低下するケースが確認されました。
この課題を解決するために、より効率的なスケーリング戦略を実装しました。具体的には、ワークロードを 2 つの独立した vLLM インスタンスに分割し、それぞれに 64 コアを割り当てます。これらのコアを「インターリーブ」し、それぞれのローカル メモリに割り当てることで、全体のスループットを大幅に向上させました。この手法により、DRAM のメモリ帯域を最大限に活用しつつ、同期処理のオーバーヘッドを削減し、ハードウェアの性能を最大限に引き出すことが可能になります。最新のベンチマークでも、このマルチ インスタンス構成が高コア数 CPU の性能を最大限に引き出す鍵であることが示されています。
この構成は、numactl を使用して各 vLLM インスタンスを特定の CPU コアおよび対応するローカル メモリに割り当てることで実現できます。以下は、前述のメモリ インターリーブ戦略を実装するための基本的な手順です。
- プラグインの導入:
既存の vLLM 環境に vLLM-ZenTorch プラグインを追加します。 - インスタンスの割り当て:
numactl を使用して、各 vLLM インスタンスを特定の CPU コアに割り当てます。 - メモリのインターリーブ:
物理コアへ非連続的にアクセスすることで、メモリ帯域がすべての DRAM チャネルに分散されるようにし、デコード処理時のボトルネックを回避します。
例えば、以下のコマンドでは、偶数番号のコア (0, 2, 4 … 126) に割り当てられた単一の vLLM インスタンスを起動し、メモリ割り当てをSocket 0 (メモリ プール 0) に制限しています:
numactl --physcpubind=$(seq -s, 0 2 127) --membind=0 \
vllm bench throughput --model meta-llama/Llama-3.1-8B-Instruct\
--random-input-len 128 --random-output-len 128 \
--num-prompts 1024 --max-num-seqs 128このパターンを用いることで、残りのコアやソケットに対応する追加インスタンスを起動し、システム全体をスケールさせることができます。この「分離 (サイロ化) 」アプローチにより、異なる AI ワークロード間でキャッシュやメモリ帯域の競合を防ぎ、サーバー全体のデコード処理のスループットを最大化できます。
さらに、CPU 推論時の性能向上のために、 export TORCHINDUCTOR_FREEZING=1 を設定してフリーズ機能を有効化しました。この環境変数は vLLM 0.12.0 以降で利用可能です。詳細はこちらでご確認いただけますが、簡単に言うと、フリーズ機能によりランタイムがモデル パラメータを不変として扱えるようになります。これにより、メモリ使用量の削減とキャッシュの局所性の向上が期待でき、モデル データがよりコンパクトに保持され、AMD EPYC プロセッサーの L3 キャッシュ内に収まりやすくなります。
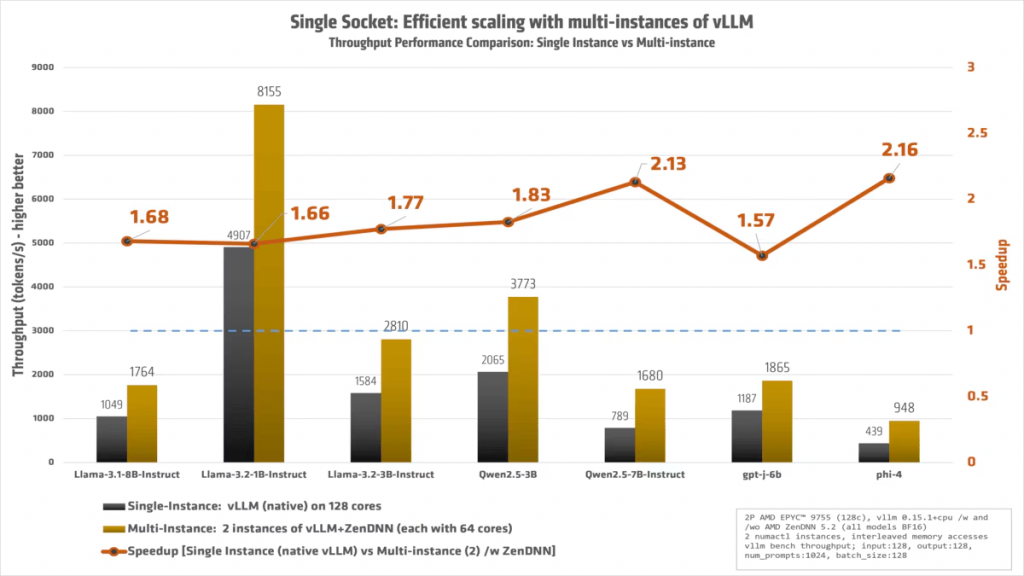
図2:1 ソケットでの分析:128 コアすべてを使用する単一の標準の vLLM と、64 コアずつ使用し ZenDNN で高速化した 2 インスタンス構成の比較
今回の検証ではデュアル ソケット構成のシステムを使用しました。さらに性能を引き出すことはできるでしょうか?答えは Yes です。
2 ソケット構成の AMD EPYC™ システムの性能を最大限に引き出すため、すべてのコアをフルに活用し、それぞれが最大効率で動作するよう最適化を行いました。
結果:
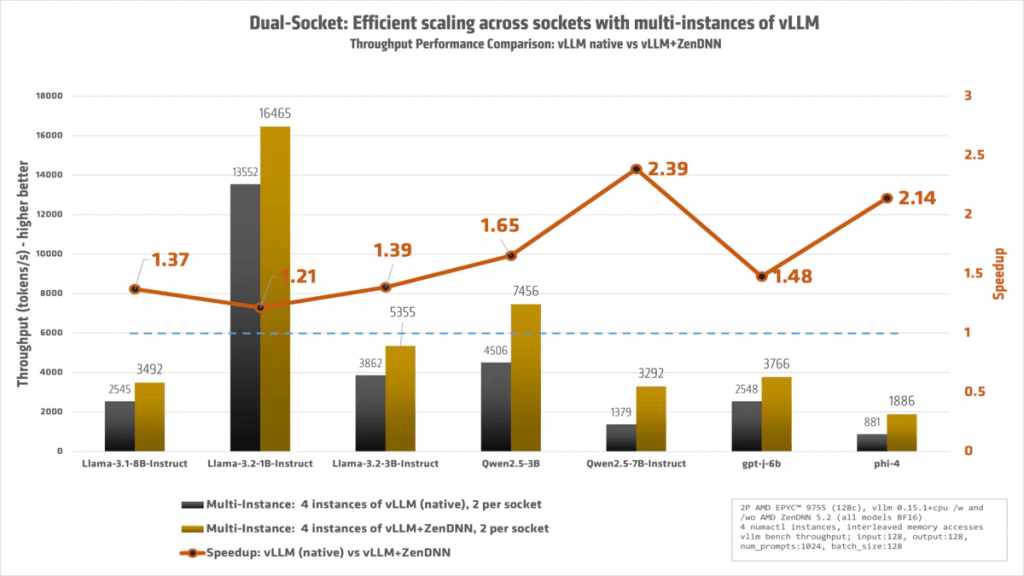
図3:デュアル ソケットでの分析:各テスト ケースでは、各ソケットに 2 つずつ、合計 4 つの vLLM インスタンスを起動し、それぞれのインスタンスがコアへインターリーブ方式でアクセスします。違いは ZenDNN の有無のみです。高速化のグラフが示すとおり、ソフトウェア最適化の有効性が確認できます。
まとめ ― 柔軟な AI 活用の未来へ
ZenDNN 5.2 のリリースは、AI インフラのあり方に対する考え方を大きく変える転機となります。GPU は依然として大規模な並列処理ワークロードにおいて事実上の標準である一方で、CPU は補助的な役割から、自ら十分な処理能力を担える高性能エンジンへと進化しています。200% を超える性能向上に加え、vLLM や Llama.cpp といった主要フレームワークとのシームレスな統合により、開発者は用途に応じて最適な環境で高度な AI を実行できるようになります。高密度なデータ センターはもちろん、エッジ環境においても同様です。
エコシステムへの継続的な取り組み
バージョン 5.1 と同様に、私たちの戦略はオープン ソース コミュニティを中心に据えています。ZenDNNL の Low Overhead API (LOA) やプラガブル デバイスに関する最適化は、引き続き PyTorch や TensorFlow のコア コードベースへ upstream (上流反映) し続けています。これにより、特定のソフトウェア スタックに依存することなく、すべての開発者がその恩恵を受けられるようになります。これらのフレームワークのネイティブ機能を強化することで、AMD ハードウェアの性能向上にとどまらず、AI エコシステム全体の進化にも貢献しています。
あらゆる環境で実現される実用的な価値
今回の技術的な進化 ― 実験的な INT4 量子化の導入や、NUMA を意識したメモリ インターリーブといったアーキテクチャ レベルの工夫 ― は、実際のビジネス価値に直結します。すでに導入済みの AMD EPYC™ ハードウェアを活用することで、エージェント型 AI やオフライン環境において、より高いスループットと低遅延を実現できます。
さっそく試してみましょう
ぜひこれらの性能向上を実際に体験してください。AMD ZenDNN Plugin for PyTorch (zentorch) および AMD ZenDNN Plugin for TensorFlow (zentf) をダウンロード (pip install または GitHub から取得) し、最新の最適化をお試しください。また、x86 アーキテクチャの可能性をさらに広げる取り組みに、ぜひご参加ください。
今すぐ試す:
- ダウンロード:GitHub リポジトリはこちら
- ドキュメント:ZenDNN 5.2 のリリース ノートを確認
パフォーマンスがどのように向上したか、ぜひ共有してください。GitHub ページで Issue を作成するか、ディスカッションにもご参加ください。
注記
本テストは、2026 年 3 月 10 日時点で AMD により社内環境にて実施されたものです。本構成における環境設定は以下のとおりです。
vLLM ベンチマーク (スループット測定):入力 128、出力 128、num_prompts: 1024、batch_size: 128。
オペレーティング システムは Ubuntu 22.04 LTS。SMT を有効化し、2 つの NUMA ノードを備えた 2 ソケット構成の AMD EPYC™ 9755 (128 コア) プロセッサー・システム上で実行。Python 3.13、zenTorch 5.2、vLLM 0.15.1+cpu を使用。データ型は BFloat16。
すべての性能指標は、1 秒あたりのトークン数 (tokens per second) によるスループットに基づいています。
結果は、システム構成および設定により異なる場合があります。
AMD Zen Software Studio サポート サービス
エクセルソフトは AMD と提携し、HPC クラスター システムやデータ センター向けに AMD EPYC™ CPU ベースのサーバー上で動作するアプリケーションのパフォーマンスを最適化するためのソフトウェア開発ツール スイート 「AMD Zen Software Studio」 のサポート サービスを提供しています。サポート サービス導入前のご質問やご購入前の見積依頼などございましたら、エクセルソフトまでお気軽にお問合せください。