
この記事では、構造化データを中断することなく PDF を Office ドキュメントに効率的に変換する C# プロジェクトを一からセットアップする方法を紹介します。示されているオプションは、ボーンデジタル PDF とスキャンされた PDF の両方で機能します。
デジタル時代では、ドキュメントを扱う際にさまざまな形式を扱うことが多くなります。PDF (Portable Document Format) はプレゼンテーションやアーカイブに優れていますが、場合によってはこれらのドキュメントを編集する必要があります。
PDF ドキュメントは多くの場合直接編集できますが、利用可能なスペースに収まりきらないほど多くのテキストが含まれるような重要な変更や、番号付きリスト内の項目の変更は、非常に困難で手間がかかり、正しく見えるようにするために長い時間がかかる場合があります。
幸いなことに、Apryse SDK では PDF を Office へ変換する仕組みを提供しています。Apryse SDK は、C#、C++、Python、Go、Ruby、JavaScript を含む複数のプログラミング言語で利用可能です。
この記事では以下を説明します:
- なぜ PDF を Office に変換すると便利なのか
- PDF を Word に変換する簡単な C# プロジェクトをゼロから作成
- PDF から他の形式のドキュメントを作成するためのオプションについて
PDF から Office への変換に Apryse を使用する理由
Apryse は、PDF 操作およびドキュメント生成ツールの主要プロバイダーとしての評判を獲得しており、その C# ライブラリはその機能を .NET 開発の領域まで拡張しています。
さらに、Apryse の高度なドキュメント処理機能を使用すると、Office を PDF 変換するだけでなく、形式と構造を維持しながら PDF からドキュメントを再構築することもできます。
2021 年の Solid Documents の買収により、Apryse は世界最高のドキュメント再構築ライブラリが利用できるようになり、これは現在、Apryse SDK 内のオプションのモジュールとして利用可能です。
PDF からドキュメントを再構築するためのサンプル プロジェクト
Apyse C# SDK は、Windows、Linux、macOS で利用できます。実際の SDK に加えて、PDF を Office に変換するだけでなく、ドキュメントの表示、編集、操作、CAD 図面の表示、その他多くの機能など、SDK の機能を示す豊富な例が用意されています。
この記事では、 PDF から Office ドキュメントを再構築するサンプルを見ていきます。Office ドキュメントを PDF に変換する方法はこちらをご覧ください。
セットアップを簡素化するために、サンプル コードではハードコーディングされたファイルを使用し、出力をハードコーディングされた場所に配置します。実際のシナリオでは、どの PDF を変換するか、生成された Office ドキュメントをどうするかを指定することも可能です。したがって、サンプル コードは、ドキュメント処理ソリューション全体の記述方法のテンプレートとしてではなく、ファイルを変換して結果を確認する方法の例として見る必要があります。
はじめに
Apryse アカウントをまだお持ちでない場合は、https://dev.apryse.com にアクセスして新しいアカウントを登録してください。これにより、デモ機能を有効にするために Apyse SDK で使用されるデモ ライセンス キーを付与できるようになります。
この記事では、 Windows 上で一からシンプルなアプリを作成します。
必要に応じて、多くの SDK サンプルの 1 つとして同梱されている事前に構築されたサンプル PdfToOfficeTest を使用できます。
この記事では、開発には VSCode を使用し、Apryse SDK をインストールするには NuGet を使用します。
前提条件
C# 拡張機能 (または別の IDE) がインストールされた VSCode が必要です。.NET Framework のバージョンもインストールする必要があります (本記事では .NET 8.0 を使用)。
プロジェクトのセットアップ
- myNetCorePDFToOffice という名前の新しいフォルダを作成します。
- VSCode 内でそのフォルダを開きます。
ターミナル内で「dotnet new console –framework net8.0」と入力します。これにより、スタブ プロジェクトが作成されます。
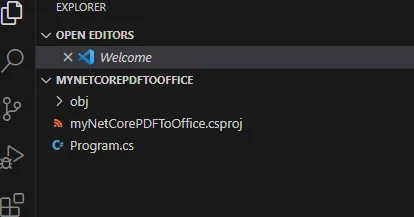
ターミナルで、dotnet add package PDFTron.NET.x64 を使用して Apryse ライブラリをダウンロードします。これにより、NuGet を使用して最新バージョンがインストールされます。
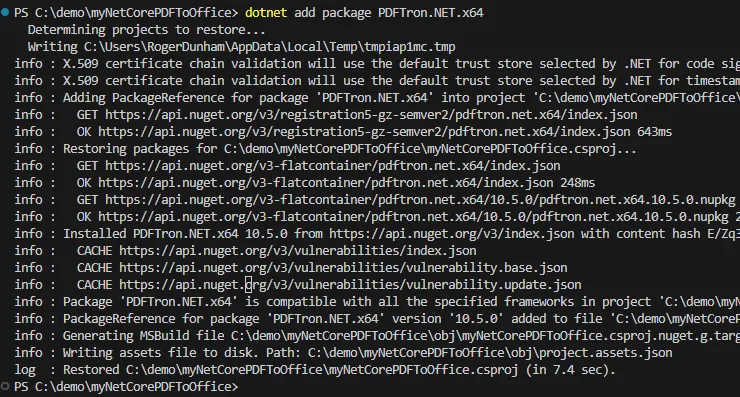
構造化出力モジュールを取得します。PDF から Office への変換は構造化出力モジュール内で実行されますが、NuGet からはアクセスできず、Apryse Web サイトから手動でダウンロードする必要があります。これは、お使いのプラットフォームのページの「モジュール」セクションにあります (例: https://dev.apryse.com/windows )。
モジュールのダウンロードが完了したら、アーカイブを解凍します。ファイルがどこにあるかを知っておく必要があります。本記事では、それらをプロジェクト フォルダを兄弟ディレクトリに配置しました。
次のコードを program.cs にコピーします。このコードは非常に基本的な例であり、サポートされている無数のオプションは示されていません。これは、PDF からの Office ドキュメントの作成を最も簡単に示すことのみを目的としています。
前にダウンロードしたライセンス コードを更新します (または、その部分をスキップした場合は、こちらから取得できます)。
using System;
using pdftron;
using pdftron.PDF;
namespace PDFToOfficeTestCS
{
class Class1
{
private static pdftron.PDFNetLoader pdfNetLoader = pdftron.PDFNetLoader.Instance();
static Class1() { }
/// <summary>
/// The main entry point for the application.
/// </summary>
static int Main(string[] args)
{
PDFNet.Initialize([Your license key]);
PDFNet.AddResourceSearchPath("../Lib/");
if (!StructuredOutputModule.IsModuleAvailable())
{
Console.WriteLine("Unable to run the sample:");
Console.WriteLine("Structured Output module not available.");
Console.WriteLine();
return 0;
}
try
{
pdftron.PDF.Convert.ToWord("./TestFiles/ paragraphs_and_tables.pdf", "./TestFiles/ paragraphs_and_tables.docx");
}
catch (pdftron.Common.PDFNetException e)
{
Console.WriteLine(e.Message);
}
catch (Exception e)
{
Console.WriteLine("Unrecognized Exception: " + e.Message);
}
PDFNet.Terminate();
Console.WriteLine("Done.");
return 1;
}
}
} 注: このサンプル コードには、変換されるファイルの場所がハードコーディングされており、TestFiles というフォルダに配置される必要があります。変換されたファイルは同じフォルダに配置されます。
dotnet run を使用してプログラムを実行します。(注: F5 を使用すると、VSCode がデバッグをサポートするためにいくつかの追加ファイルを追加しようとしていることが通知されますが、これは問題ありません。)
しばらくすると、新しい DOCX ファイルが表示されます。Structured Output モジュールは自己完結型であり、Office (またはその他の Word 処理パッケージ) をマシンにインストールする必要はありません。
ファイルを開いてみましょう。Office がインストールされていない場合は、そのファイルを別のマシンにコピーして実行できます。
10.6.0 より前のバージョンの Apryse では、変換に試用版ライセンス キーが使用された場合、生成されたドキュメントに乱雑な単語が含まれる可能性があり、これが表示された場合は、SDK および構造化出力モジュールの最新バージョンに更新してください。
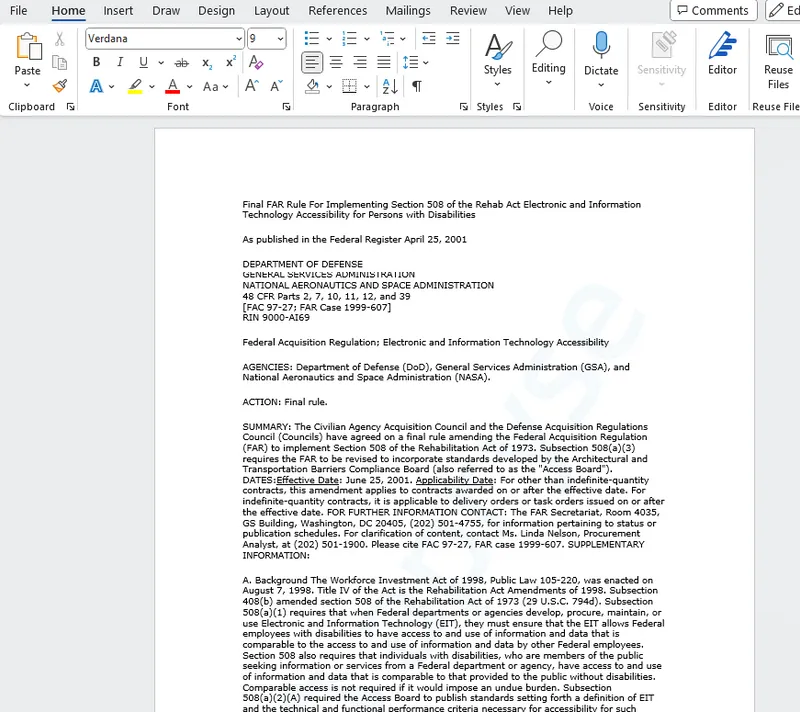
Word が再作成されただけでなく、新しいドキュメントでも改行と段落の区切りが PDF の場合と同じになっています。
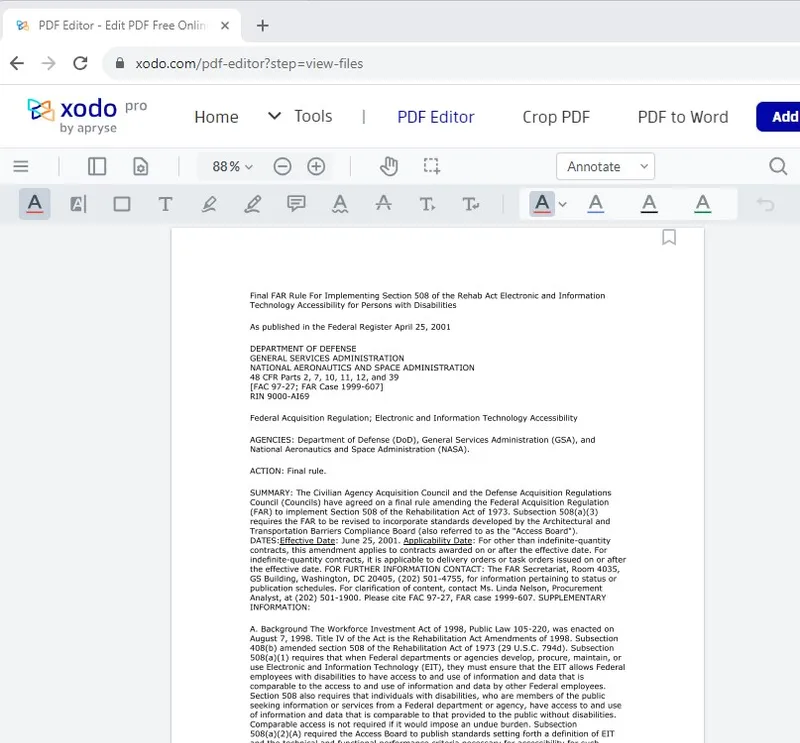
これは、元の作成者が意図的にドキュメントを特定の方法で設定した場合、それが可能であれば、再構成されたドキュメントは同一に見えることを意味します。(特にドキュメントが Word として開始されていない場合、または PDF が手動で編集された場合など、レイアウトを正確に再構築できない場合があります。)
これで、PDF とまったく同じように、必要に応じて編集可能なドキュメントが完成しました。素晴らしい結果ですね!
スキャンした PDF を Word に変換することは可能ですか?
もちろんです!
構造化出力モジュールは、スキャン品質が十分に良好であれば、余分な労力やコーディングを行わずに、OCR (光学文字認識) を使用してスキャンした PDF から Word を再構築できます。これは英語文書に限らず、多くの場合、文書言語は自動的に検出されるため、指定する必要さえありません。
さらに、このテクノロジーは、スキャンされた画像から Word の機能を推測できるほど賢いものです。
たとえば、行の前に数字が付いている行がある場合、それらは番号付きリストとして解釈できます。

新しい項目が追加されるか、既存の項目がリストから削除または移動されると、Word 自体が自動的に再番号付けを処理するため、これは編集の観点からは素晴らしいことです。

それによってどれだけの時間が節約されるか想像してみてください。
PDF を Excel、PowerPoint、その他の種類のドキュメントに変換
PDF を Word に変換するだけでなく、SDK は PDF から Excel および PowerPoint に変換することもでき、従来の Office 形式 (.doc、.xls、.ppt) もサポートします。
これらの他の形式に変換するには、適切な「To」メソッドを使用し、ソース PDF と出力ファイルの名前を渡します。
たとえば、ToExcel メソッドを使用した次のコードは、PDF をスプレッドシートに変換します。
pdftron.PDF.Convert.ToExcel("./TestFiles/Cashflow.pdf", "./TestFiles/CashflowConv.xlsx"); 
これは、Apryse 内で PDF から表形式データを抽出する唯一の方法ではありません。詳細については、Intelligent Document Processing (IDP) アドオンを使用したデータの抽出に関する記事を参照してください。これらのツールはさまざまな方法で機能するため、一方のツールで必要なものがすべて提供されなくても、もう一方のツールで提供できる可能性があります。
PowerPoint プレゼンテーションは、 ToPowerPoint メソッドを使用して再構築することもできます。
pdftron.PDF.Convert.ToPowerPoint("./TestFiles/WW1Cryptography.pdf", "./TestFiles/WW1CryptographyConv.pptx" 
ドキュメント生成時の変換オプションの使用
上記の方法は非常に簡単です。変換はわずか 1 行のコードを使用して実行されました。
ただし、PDF を Office ドキュメントに変換する場合には、多くのオプションを使用できます。https://docs.apryse.com/documentation/samples/dotnetcore/cs/PDF2OfficeTest/ のサンプル コードは、たとえば、元の PDF のページのサブセットのみを使用して変換を調整する方法を示しています。
結論
Apryse の C# ライブラリを使用すると、開発者は Apryse SDK の堅牢な機能を活用して、PDF から Office ドキュメントを効率的かつ簡単に再構築できます。
ドキュメント回復ツール、コンテンツ抽出アプリケーション、またはドキュメントの逆変換を必要とするその他のソリューションを構築している場合でも、Apryse はタスクを効率的に実行するために必要なツールを提供します。
Apyse のパワーと C# の多用途性を活用することで、ドキュメント処理ワークフローに柔軟性と効率性をもたらし、ユーザーのエクスペリエンスと生産性を向上させることができます。
Apryse Structured Output モジュールの機能と、特定の要件に応じて再構築プロセスをカスタマイズする方法についての詳細な洞察を提供するドキュメントも豊富にあります。
本製品に関するご質問、ご不明な点はエクセルソフトまでお気軽にお問い合わせください。
Apryse 製品の詳細は、弊社 Web サイトをご確認ください。
記事参照:
© 2023 Apryse
「PDF to Office Document Conversion using Apryse and C# on .NET Core – Building a Sample from Scratch」
