

決定木に対する勾配ブースティングは、分類や回帰のための最も正確で効率的なマシンラーニング・アルゴリズムの 1 つです。勾配ブースティングには多くの実装がありますが、最も人気があるのは XGBoost (英語) および LightGBM (英語) フレームワークです。この記事では、インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) を使用して、XGBoost または LightGBM モデルの予測速度を最大 36 倍まで向上させる方法を紹介します。
勾配ブースティング
XGBoost や LightGBM の勾配ブースティングは、現実世界のさまざまな問題を解決するため、また、研究を行うため、そして Kaggle* (英語) コンテストに参加するために、多くの人が使用しています。これらのフレームワークは優れたパフォーマンスを発揮しますが、その予測速度はまだ改善の余地があります。予測は、マシンラーニングのワークフローの中で最も重要な段階であることを考えると、パフォーマンスの向上は有益なものです。
インテル® oneDAL は競合他社に比べて数倍の速度で勾配ブースティング推論を行います (高速勾配ブースティング木推論 (英語)) このパフォーマンス上のメリットが、XGBoost と LightGBM でも利用できるようになりました。
モデル・コンバーター
すべての勾配ブースティングの実装は、同様の操作を行うため、データの保存方法も同様です。理論的には、これにより、学習したモデルをあるマシンラーニング・フレームワークから別のフレームワークに変換することが容易になります。インテル® oneDAL のモデル・コンバーターは、XGBoost や LightGBM で学習したモデルを、たった 1 行のコードでインテル® oneDAL に転送できるように設計されています。ほかのフレームワークのモデル・コンバーターも近日中に利用可能になる予定です。
この例では、XGBoost と LightGBM モデルをインテル® oneDAL に変換する方法を紹介します。
まず、Python* 3.6 以上に対応した最新バージョンの daal4py を入手します。
conda install -c conda-forge daal4py'>=2020.3'
XGBoost モデルをインテル® oneDAL に変換:
# Train an XGBoost model import xgboost as xgb clf = xgb.XGBClassifier(**params) xgb_model = clf.fit(X_train, y_train) # Convert the XGBoost model to a oneDAL model import daal4py as d4p daal_model = d4p.get_gbt_model_from_xgboost(xgb_model.get_booster()) # Make a faster prediction with oneDAL deel_prediction = d4p.gbt_classification_prediction(nClasses=n_classes) .compute(X_test, daal_model).prediction
LightGBM モデルをインテル® oneDAL に変換:
# Train a LightGBM model import lightgbm as lgb lgb_model = lgb.train(params, lgb.Dataset(X_train, y_train)) # Convert the LightGBM model to a oneDAL model import deel4py as d4p daal_model = d4p.get_gbt_model_from_lightgbm(lgb_model) # Make a faster prediction with oneDAL daal_prediction = d4p.gbt_regression_predition().compute(X_test, daal_model).predition
注) トレーニングや予測の際に欠損値 (NaN) を使用することに一時的な制限があります。データに欠損値があると、推論の質が低下する可能性があります。
インテル® oneDAL からモデルを保存・読み込みする方法の一例:
# Model from XGBoost
daal_model = d4p.get_gbt_model_from_xgboost(xgb_model)
import pickle
# Save model to a file
with open('model.pkl','wb') as out:
pickle.dump(daal_model, out)
# Load model from a file
with open('model.pkl','rb') as inp:
model = pickle.load(inp)
# Make predictions
daal_prediction =
d4p.gbt_regression_prediction().compute(X_test, model)
デフォルトでは、インテル® oneDAL は予測された要素のラベルのみを返します。確率も必要な場合は、明示的に要求する必要があります。
# List all results that you need by placing '|' between them:
predict_algo = d4p.gbt_classfication_prediction(nClasses=n_classes,
resultsToEvaluate="computeClassLabels|computeClassProbabilities")
daal_prediction = predict_algo.compute(X_test, model)
# Get probabilities:
probabilities = daal_prediction.probabilities
# Get labels:
labels = daal_prediction.prediction
パフォーマンスの比較
インテル® oneDAL のパフォーマンスが XGBoost や LightGBM よりも優れていることは、以下のデータセットを使って実証されています。
・Mortgage (45 個の特徴、900 万個の観測値)
・Airline (691 個の特徴、ワンショット・エンコーディング、100 万個の観測値)
・Higgs (28 個の特徴、100 万個の観測値)
・MSRank (136 個の特徴、300 万個の観測値)
モデルは、XGBoost と LightGBM で学習した後、daal4py に変換しました。オリジナルの XGBoost/LightGBM モデルと daal4py で変換されたモデルのパフォーマンスを比較するために、オリジナルのモデルと変換されたモデルの両方の予測時間を測定しました。図 1 によると、daal4py は XGBoost よりも最大 36 倍 (平均 24 倍)、LightGBM よりも最大 15.5 倍 (平均 14.5 倍) 高速であることがわかります。予測の質は変わりません (回帰では平均二乗誤差、分類では精度とロジスティック損失で測定)。
インテル® oneDAL は、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) 命令セットを使用して、インテル® Xeon® プロセッサーにおける勾配ブースティングのパフォーマンスを最大限に引き出します。比較やランダム・メモリー・アクセスなど、最も一般的に使用される推論操作は、インテル® AVX-512 の vpgatherd{d,q} 命令と vcmpp{s,d} 命令を使用して効果的に実装できます。また、パフォーマンスはストレージの効率やメモリーの帯域幅にも依存します。木構造の場合、インテル® oneDAL はメモリー内のデータをスマートロックすることで、一時的なキャッシュ・ローカリゼーション (木のサブセットと観測値のブロックが L1 データキャッシュに格納されている状態) を実現しています。この動作により、ほとんどのメモリーアクセスが、メモリー帯域幅が最も高い L1 レベルで直ちに満たされます。
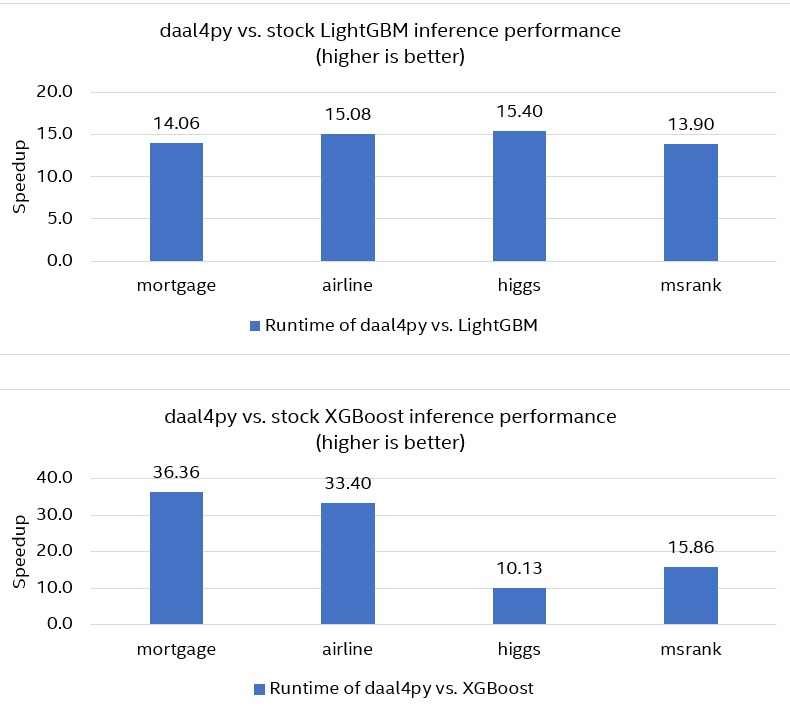
図 1. オリジナルの XGBoost/LightGBM モデルと daal4py で変換されたモデルの推論パフォーマンスの比較
まとめ
多くのアプリケーションでは、XGBoost や LightGBM を使って勾配ブースティングを行っていますが、モデル・コンバーターを使うことで、インテル® oneDAL を使った推論を簡単に高速化することができます。モデル・コンバーターを使うと、XGBoost と LightGBM のユーザーは以下のことができます。
・既存のモデルのトレーニング・コードを変更せずに使用
・コードの変更を最小限に抑え、品質を損なうことなく、最大 36 倍の推論速度を実現
ハードウェアとソフトウェアの構成
インテル® Xeon® Platinum 8275CL プロセッサー (第 2 世代インテル® Xeon® スケーラブル・プロセッサー): 2 ソケット、ソケットあたり 24 コア
インテル® ハイパースレッディング・テクノロジー: 有効
インテル® ターボ・ブースト・テクノロジー: 有効
オペレーティング・システム: Ubuntu* 18.04.4 LTS (Bionic Beaver)、合計メモリー 192GB (12 スロット/16GB/2933MHz)
ソフトウェア: XGBoost 1.2.1、LightGBM 3.0.0、daal4py バージョン 2020 Update 3、Python* 3.7.9、NumPy 1.19.2、pandas 1.1.3、scikit-learn 0.23.2
トレーニング・パラメーター: XGBoost (英語) および LightGBM (英語)
インテル® oneAPI に関する詳細はこちらからご参照ください。
参照記事:
Improve the Performance of XGBoost and LightGBM Inference