

フィールド・プログラマブル・ゲート・アレイ (FPGA) は、多種多様なワークロードでハイパフォーマンスを実現できる柔軟なハードウェア・プラットフォームです。この記事では、インテル® oneAPI を使用して実装されたインテルの Gzip 設計例と、インテル® oneAPI によって FPGA がどのように利用しやすくなるかについて説明します。(oneAPI の詳細については、「インテル® oneAPI を使用したヘテロジニアス・プログラミング」を参照してください。)
設計例では、多くのストレージやネットワーク・アプリケーションに不可欠な可逆データ圧縮アルゴリズムである DEFLATE を実装しています。この設計例は SYCL* で記述され、oneAPI DPC++ コンパイラーを使用してコンパイルされており、圧縮時間を大幅に短縮しながら、優れた圧縮率を実現しています。Gzip の設計例では、FPGA で利用可能な空間の超並列処理を利用して、メモリーアクセス、辞書検索、マッチングを並列化することで、LZ77 圧縮アルゴリズムを高速化しています。インテル® oneAPI を使用して実装されているため、コードはあらゆる計算技術を対象とすることができますが、ここでは特に FPGA に最適化しています。設計例では、Gzip と互換性のある圧縮データファイルを生成するため、開発者は標準的なソフトウェア・ツールを使用して、この圧縮ファイルを展開することができます。
FPGA の仕組み
FPGA は、多数の低レベルの計算子およびストレージ要素 (加算器、乗算器、論理演算、メモリーなど) を 2D アレイ状に構成し、再構成可能なルーティングで接続した再構成可能なデバイスです。これらの要素は、複雑な演算パイプラインと特殊なオンチップ・メモリー・システムを形成することができます。汎用コードを実行するように設計された従来のアーキテクチャーとは対照的に、FPGA は、ターゲット・アプリケーションのパフォーマンスを高速化するカスタム・アーキテクチャーを実装するように再構成することができます。例えば、FPGA は、クロックサイクルごとにループの反復全体を実行できる特殊な計算パイプラインを実装することができます。FPGA は、オフチップに接続メモリー (DDR4 など) やホスト CPU との接続 (PCIe* 経由) を備えたアクセラレーション・モデルに適しています。
DPC++ の FPGA へのコンパイル
インテル® oneAPI DPC++ コンパイラーの FPGA バックエンドは、指定されたコード用に FPGA を再構成するビットストリームを生成します。SYCL* プログラムの各カーネルは、FPGA リソースのサブセットを使用して実装されます。実装されたすべてのカーネルは、同時に実行することができます。
カーネル内では、各ループ本体は、ループ反復全体を処理するために必要なすべての機能ユニットを含む、深く特殊なパイプラインに変換されます。条件文は予測実行としてリファクタリングされます。パイプラインを 1 回通過するだけで、ループの繰り返し全体が実行されます。
コンパイラーは、並列に実行可能な命令を識別し、それらを同じパイプライン・ステージに配置することで、複数の機能ユニット上で並列実行できるようにします。さらに、データを転送できるようにしてパイプラインを最適化し、後続のループ反復がデータハザードなしにできるだけ早く (多くの場合、連続したサイクルで) 実行できるようにします (図 1)。
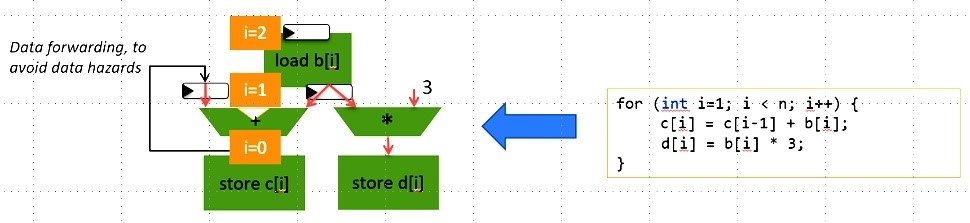
図 1. ユーザーコードから生成されたパイプライン
FPGA 向けのコンパイルには通常数時間かかります。開発サイクルを短縮するために、FPGA バックエンドには、最適化の判断材料となるエミュレーター、スタティック・パフォーマンス・レポート、ダイナミック・プロファイラーが付属しています。エミュレーションやスタティック・レポートの生成は数分で済み、従来の RTL 開発フローと比較して、FPGA アプリケーション開発の生産性が大幅に向上します。
インテル® oneAPI の強み
Gzip の設計では、シングルソース設計や複数のアクセラレーターに加え、アクセラレーターがホットスポット・コードを実行し、CPU が非ホットスポット・コードを処理するようなヘテロジニアス・コンピューティングなど、インテル® oneAPI プログラミング機能を最大限に活用します。Gzip 設計はインテル® oneAPI を使って書かれているので、ハードウェア変換はコンパイラー・バックエンドに任せて、アルゴリズムの詳細に集中して C++ で FPGA 向けのコンパイルに適したアルゴリズムを記述できます。アルゴリズムは C++ で表現されているので、その機能が正しいかどうかをテストすることができます。また、ハードウェア・コンパイルする前に、レポートを見てハードウェアのパフォーマンスを予測することができます。
設計例
Gzip 設計のアーキテクチャーは、DEFLATE のデータフローに従います。作業を行うために 3 つのカーネルを作成します。
- LZ77
- Huffman
- CRC
最初のカーネルは、LZ77 データを計算して、ファイルから重複する配列を検索し、排除します。その考え方を図 2 に示します。

図 2. LZ77 圧縮の例
重複シーケンスは、前に出現したものとの相対的な参照で置き換えられます。参照のエンコードに必要なストレージはオリジナルのテキストよりも少なくて済むため、ファイルサイズが小さくなります。
一致を見つけるためには、これまでに見たすべてのシーケンスを記憶しておき、最良の一致候補を選ぶ必要があります。そして、そのシーケンスを置き換えて、現在の一致の終わりから、あるいは良いマッチが見つからなかった場合は次のシンボルから、マッチング処理を続けます。これは容易ではありません。
私たちの目標は、FPGA のクロックサイクルごとに 16 バイトを処理することです。つまり、1 クロックサイクルで、次のことが必要です。
- 16 個の開始点それぞれで、最良の一致を見つけるため、履歴を確認する
- (オーバーラップしない) 最良の 1 つ以上の一致を選択する
- 結果を出力に書き込む
- 読み込んだ文字列を辞書に格納する
一致はオーバーラップできないので、この作業を並列に動作させることができるかどうかは明らかではありません。特定のバイトから始まる一致は、それ以前の一致がすでにカバーしていないことがわかるまで、選ぶことができません。(この点については次のセクションで詳しく説明します。)
2 つ目のカーネルは、データにハフマン符号化を適用して、最終的な圧縮結果を生成します。この処理中、すべてのシンボルと参照が可変幅符号化に置き換えられ、最も頻繁に使用されるシンボルに対してより少ないビット数のコードが提供されるため、ファイルサイズがさらに小さくなります。この処理を並列化する方法は簡単です。16 個 (またはそれ以上) の独立したハードウェア・ユニットを用意し、それぞれで指定されたシンボルのハフマン符号を決定します。しかし、まだ問題があります。出力の長さが可変なので、最終的には各出力を出力ストリームの正しい位置に書き込む必要がありますが、そのためには前の出力の大きさを知る必要があります。また、ハフマン符号はバイト境界でアライメントされていないので、多くのビットレベルでの操作が必要になります。ここでは詳しく述べませんが、基本的にこの処理は LZ77 ほど複雑ではありません。
最後に、3 つ目のカーネルが入力データに対して CRC-32 を計算します。このカーネルはほかの 2 つのカーネルとは独立しており、並列に動作させることができます。また、FPGA への実装も比較的簡単なので、ここでは詳細を説明しません。
FPGA に最適化された LZ77 の実装
データ処理のシーケンシャルな性質を示すために、LZ77 エンコーダーは単一のメインループを持つ単一つのタスクとして記述されています。コードは、単一スレッドを使用して、ファイル全体でシンボルを 1 つずつ反復します。前出のシーケンスをデータファイルに格納するため、辞書のセットを作成します。これらの辞書は、ハッシュマップのように、格納されているデータのハッシュでインデックスされています。ただし、パフォーマンス上の理由から、より最近の (重複する) エントリーは、同じハッシュキーを持つ以前の入力に対応する辞書データを上書きします。辞書の更新は、新しく見た入力をすべての辞書に書き込むことで行われます。重複を軽減するために、前出のシーケンスは複数の互いに重複しないセットに分割します。
なぜ複数の辞書が必要なのでしょうか? 1 サイクルで 16 バイトを処理するには、16 個の文字列 (各バイトから始まるもの) を辞書に格納し、クロックサイクルごとに 16 回のハッシュ・ルックアップを行うことになります。各 FPGA メモリーブロックには 2 つのポートしかありません。これらの同時アクセスを可能にするために、16 個の独立したメモリーシステムを作り、それぞれが異なる位置に文字列を格納します。履歴が 16 個の辞書にまたがっているので、16 回のハッシュ・ルックアップはそれぞれ 16 個の異なる辞書で行う必要があり、合計 256 回の検索を行うことになります。これにより問題がより複雑になったように見えるかもしれません。
これを解決するには、各辞書のコピーを 16 個、合計 256 個の辞書を構築します。これらの辞書はすべて、FPGA のオンチップメモリーの大部分を使用しますが、16 個のハッシュ・ルックアップとライトを毎クロックサイクルで実行するという目標は達成できました。図 3 は、1 クロックで 4 バイトを処理する場合の辞書構造の例です。(ちなみに、辞書専用の FPGA 領域は、1 サイクルあたり 16 バイトを超える処理を妨げる主な要因です。)
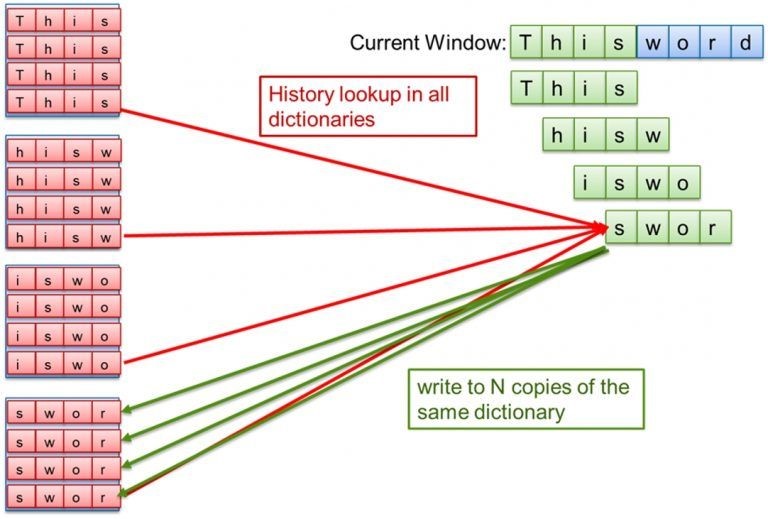
図 3. 4 バイト並列アクセスのための辞書の複製
並列動作を表現するのは難しいと思われるかもしれません。しかし実際には、コンパイラーがルックアップ間のデータ並列性を識別します。つまり、このコードは、すべての辞書ルックアップを同時に実行できる特殊な FPGA ロジックを用いているのです。このコードでは、VEC は 1 サイクルあたりの処理バイト数、LEN は文字列のサイズを表しています。今回の設計例では、両方とも 16 に設定されています。テンプレート・メタプログラミング (アンローラー) を使用して、すべての i と j に対して内部関数のコードを複製しました。
辞書を使うことで 1 つの問題は解決しますが、各クロックサイクルで完全なループの反復を完了させたい場合は、さらに多くの処理が必要になります。しかし、追加の作業は必要ありません。FPGA コンパイラーは、データパスを自動的にパイプライン化します。そのため、ループの反復 0 が辞書からの読み込みを終えると、反復 1 が開始され、反復 0 は最適なマッチの選択を開始します。一致したものを選択する作業は、複数のサイクルにわたって段階的に行われ、各段階で異なる反復のループが処理されます。
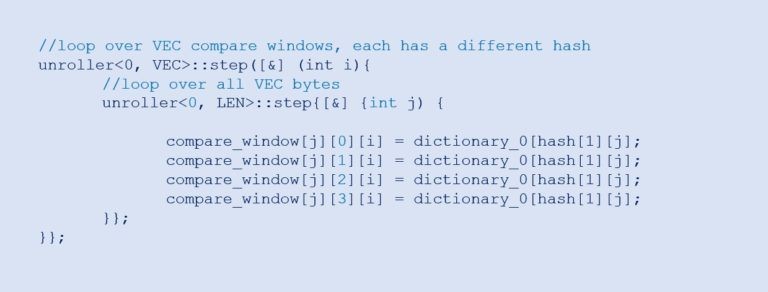
図 4
出力を生成する際の最後の課題は、後続の一致に与える影響を正しく考慮することです。一致が特定されると、重複する一致は無視されなければなりません。single_task のコード表現では、これはループ伝播変数として現れ、ループの後続の反復が進む前に計算する必要があります。この計算が複雑すぎると、FPGA のクロック速度が制限されたり、ループの反復をすべてのクロックサイクルで完了させることができなくなったりします。
FPGA をターゲットにしているため、この依存関係の処理を最適化するようにハードウェアをカスタマイズすることができます。また、データに依存する計算量を最小限に抑えることで、データハザードを単純化しています。例えば、ハッシュ・ルックアップを投機的に行い、可能性のあるすべての一致を決定することにしました。オーバーラップする一致は後から排除します。FPGA バックエンドは、必要なフォワーディング・ロジックを最適化し、データハザードを完全に回避します。図 4 は、投機的な一致の排除を示しています。
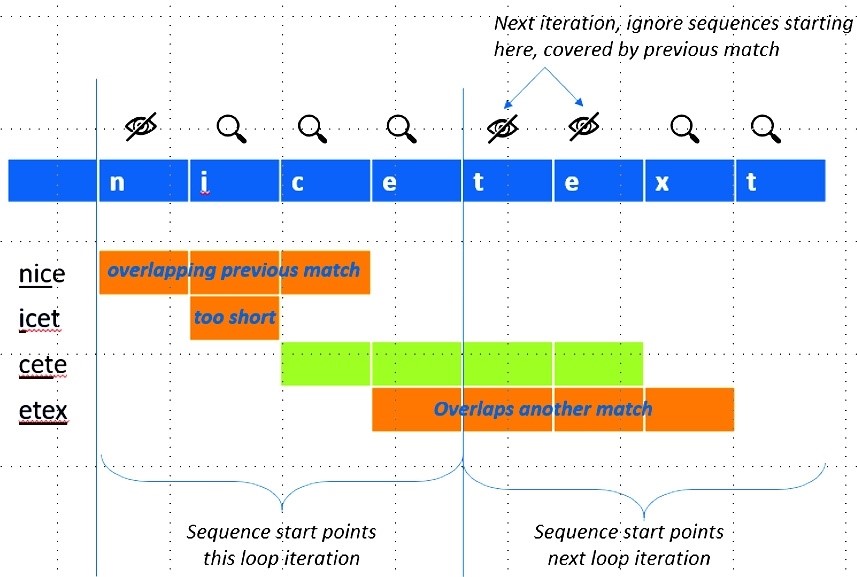
図 5. 以前のループ反復で特定された一致、現在のループ反復でオーバーラップした一致、および質の悪い一致を考慮して、投機的な一致を排除
タスクレベルの並列処理
ファイルを圧縮するために、ホスト CPU は 3 つの処理カーネルを非同期的に投入します。これらのカーネルは、FPGA ハードウェア内で同時に実行することができます。これらのカーネルの動作速度はわずかに異なり、CRC の方が高速です。LZ77 は、ハフマンカーネルが必要とするデータを生成します。追加の遅延とオフチップメモリーを介してデータを転送することを避けるために、SYCL* 言語のインテル拡張であるカーネル間通信パイプを使用しています。この拡張機能により、図 6 に示すように、オフチップメモリーに書き込むことなく、異なるカーネルがデータを順次交換することができます。

図 6. Gzip のタスク並列処理
Gzip 設計のビルド
インテル® oneAPI コードサンプルから Gzip 設計をダウンロードして実行することができます。正当性と動作の検証をするために、FPGA エミュレーションを対象とすることができます。例えば、/bin/emacs-24.3 を圧縮しようとすると、次のような結果になります。

図 7
次のステップでは、設計のスタティック最適化レポートを作成します。最適化を行う際には、このレポートを見て、カーネルに作成される特殊なパイプラインの構造を理解します。レポートは、gzip_report.prj/reports/report.html.make reports に生成されます。
最後に、設計をコンパイルして FPGA ハードウェアで実行します。最適化されたコンパイルには数時間かかります。

図 8
パフォーマンス
Gzip を起動する方法は以下の通りです。

図 9
パフォーマンスを評価するために、アプリケーションは圧縮関数を繰り返し呼び出し、全体の実行時間とスループットをレポートします。以下に出力例を示します。
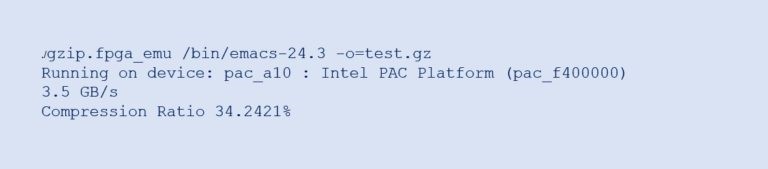
図 10
FPGA をより身近なものに
インテル® oneAPI を使えば、FPGA がこれまで以上に身近になります。空間アーキテクチャーは、著しい加速化の可能性をもたらし、多くの場合、驚異的な並列性を持たないドメインでも利用できます。これは、DPC++ コンパイラーとインテル® oneAPI により、容易に利用することができます。
