

この記事は、インテル® コミュニティーのブログに公開されている「Benchmarking BRGM’s EFISPEC3D earthquake simulation application on AWS」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
はじめに
BRGM (Bureau de Recherches Géologiques et Minières、フランス地質調査所) は、持続可能な開発のための地表および地下資源の管理に地球科学を応用する、フランスを代表する公的機関です。多くの官民関係者とのパートナーシップのもと、科学的研究に重点を置き、科学的に検証された情報を提供し、公共政策の立案や国際協力の支援を行っています。
このため、BRGM では、海面上昇、地震ハザード、建物の脆弱性など、公共政策で関心の高い、さまざまな量を評価するためのハイパフォーマンス・コンピューティング (HPC) のシミュレーションを実施する必要があります。例えば、物理学に基づく大規模な地震シナリオを実行して、地震ハザードを評価するとともに、エピステミックまたはアレオテリックな不確定要素に関して、その信頼度を定量化します。このアプローチは、一般的に国 (Tier-1) または欧州 (Tier-0) のインフラによって提供されている膨大なコンピューティング・リソースを必要とします。
本記事では、インテル® Xeon® スケーラブル・プロセッサーとインテル® oneAPI ツールキットを活用して AWS* 上で地震のシナリオを計算する BRGM の HPC アプリケーション「EFISPEC3D[1]」の計算性能についてご紹介します。
EFISPEC3D は、連続 Galerkin スペクトル有限要素法を用いて 3 次元運動方程式を解く科学コンピューター・プログラムで、MPI (メッセージ・パッシング・インターフェイス) を用いて並列化されています。
「EFISPEC3D は、ノンブロッキング通信方式と 3 レベルの MPI コミュニケーターにより、標準的なメッシュサイズ (例: 200 万個のスペクトル要素) において数千コア以上のスケールに最適化されています。1,906,624 個のスペクトル要素からなるメッシュを 27036 個の物理コアに分割した場合の性能は、物理コアあたり 70 個のスペクトル要素まで適切にスケーリングできることを示しています。」
EFISPEC3D は原子力発電所などの重要な産業施設の地震ハザード評価、緊急計算、機械学習による感度解析、複雑な地質媒体 (堆積谷、火山など) における地震波伝播など、さまざまな分野で利用されています。
EFISPEC3D は、2009 年からフランス地質調査所 (BRGM) が、インテル社、地球科学研究所 (ISTerre)、オルレアン基礎コンピューター科学研究所 (LIFO) と共同で開発しています。フランス国立研究機関 (ANR) から資金提供を受けているいくつかの研究プロジェクトの一部であり、現在も継続しています。




2 つのレベルの改良策からデザインされた、テストケース n°2 のメッシュの異なるビューは 315m から 105m までのものと、105m から 35m までのもので少なくとも 35m 以上の地震波長を考慮しています。盆地の輪郭内では、調査対象の堆積盆の最下部を含む一定の深さでメッシュを細かくしています。メッシュは 7,053,889 個の非構造六面体要素 (約 14 億自由度) からなり、この上で弱形式の運動方程式で解いています。
EFISPEC3D の AWS* への移植
ここでは、EFISPEC3D の AWS* への移植についてご紹介します。このアプリケーションのコンパイルは、クラスターの計算ノードタイプ、例えば c5n.18xlarge の AWS* EC2 インスタンスで行われます。
前提条件:
EFISPEC3D のコンパイルには、インテル® コンパイラー、インテル® MPI ライブラリーに加え、以下のライブラリーが必要となります。
zlib
slib
HDF5
METIS
NetCDF
Exodus
インテル® oneAPI ツールキット 2021 に含まれるインテル® C++ コンパイラー: これらのライブラリーにおいて最高のパフォーマンスを得るためにインテル® C++ コンパイラーの使用を推奨します。
インテル® oneAPI ツールキット 2021 に含まれるインテル® MPI ライブラリー: 使用するタイプの AWS* のインスタンス上でコンパイルすることを推奨します。
インテル® oneAPI をインストールする
AWS* EC2 インスタンスにインテル® oneAPI をインストールする手順:
- システムをアップデート:
 intel-hpckit と intel-basekit の最終バージョンのパッケージを削除:
intel-hpckit と intel-basekit の最終バージョンのパッケージを削除: 一般ユーザーとして /temp ディレクトリーに YUM (DNF) リポジトリー・ファイルを作成:
一般ユーザーとして /temp ディレクトリーに YUM (DNF) リポジトリー・ファイルを作成: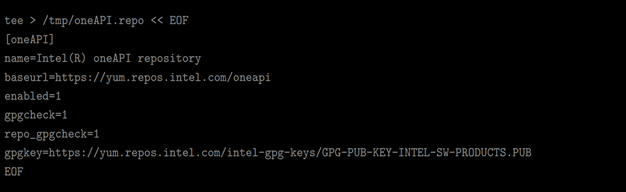 新しく作成したrepo ファイルを YUM/DNF の設定ディレクトリー /etc/yum.repos.d に移動:
新しく作成したrepo ファイルを YUM/DNF の設定ディレクトリー /etc/yum.repos.d に移動: インテル® oneAPI のコンパイラーをインストール:
インテル® oneAPI のコンパイラーをインストール: 1 セッションにつき 1 回 sh に source を実行:
1 セッションにつき 1 回 sh に source を実行:

コンパイル
EFISPEC3D をコンパイルするコマンドラインは以下のとおりです。
![]()
ここで、<efi_version> は EFISPEC3D アプリケーションのバージョン、<intel_instruction> は命令の種類 (インテル® SSE、インテル® AVX、インテル® AVX 2) を表します。
例:
![]()
デフォルトでは、インテル® SSE (インテル® ストリーミング SIMD 拡張命令) が有効になります。以下のコマンドラインは、インテル® SSE、インテル® AVX、インテル® AVX 2 命令に対応するすべての EFISPEC3D のバージョンを make します。

コンパイル後、あとでシミュレーションに使用する EFISPEC3D のバイナリーソースをすべて ZIP で圧縮します。
パフォーマンス結果
ここでは、BRGM の予測シミュレーションを行うために、AWS* のサービスを利用することを紹介します。約 300 日間の典型的なシミュレーションを、AWS* クラウド (物理コア数 27K、ハイパースレッディング・テクノロジー無効、シングルコア) 上で 25 分間で実行します。
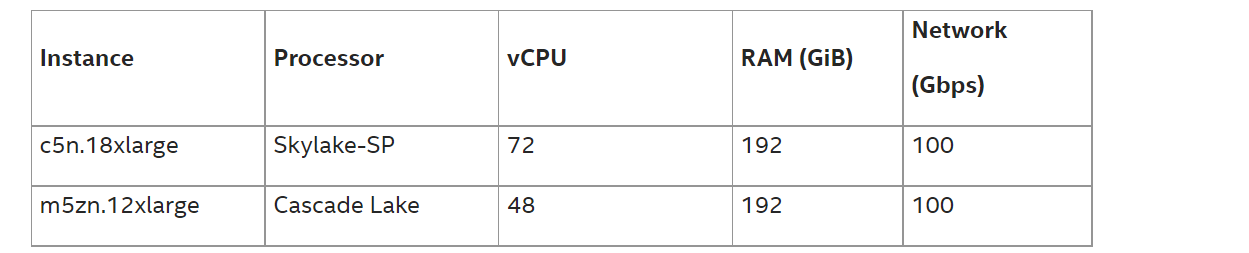
AWS* では、インテル® プロセッサー・ベースの Amazon EC2* (Amazon* Elastic Compute Cloud*) インスタンスを数種類用意しています。この性能レポートに使用されている 27K コアは、インテル® Xeon® Platinum 8000 シリーズ・プロセッサー @3.50GHz (開発コード名 Skylake-SP) を搭載した c5n.18xlarge インスタンスと、第 2 世代インテル® Xeon® スケーラブル・プロセッサー @4.50GHz (開発コード名 Cascade Lake) を搭載した m5zn.12xlarge インスタンスをベースとしています。C5n と M5zn の両インスタンスは、ノード間通信をサポートするために EFA (Elastic Fabric Adapter) [2] を使用しています。この 2 種類の、コストと性能のバランスが異なるインスタンスを選択しました。
EFISPEC3D は Fortran08 とインテル® MPI ライブラリーで実装され、スペクトル有限要素法により 3 次元波動方程式を解きます。
強力なスケーリング・シミュレーション
最初の実験では、AWS* の c5n.18xlarge と m5zn.12xlarge インスタンスで、EFISPEC3D アプリケーションの強力なスケーリングに関してテストしました。
以下のスクリプトは、c5n.x18large インスタンスのコアに対してシミュレーションを実行するバッチスクリプトの例です。
#!/bin/bash
#SBATCH --account=account-strong-scaling-16384
#SBATCH --job-name=string-scaling-16384
#SBATCH --partition=batch-c5n
#SBATCH --hint=nomultithread
#SBATCH --mem-per-cpu=2048M
#SBATCH --nodes=456
#SBATCH --ntasks=16384
#SBATCH --ntasks-per-node=36
#SBATCH --ntasks-per-core=1
#SBATCH --output=string-scaling-16384-%x_%j.out
ulimit -s unlimited
mpiexec.hydra -n 16384 /fsx/applications/EFISPEC3D-c5n-18xlarge/TEST-1-STRONG-SCALING/EFISPEC3d-ASYNC/bin/efispec3d_1.1_avx.exe
約 200 万個の六面体、約 77GiB RAM のメッシュを 1 つの物理コアから 27036 個の物理コアで解析しています。
シミュレーションは、サイズ 1.0E-03 の 101 回のタイムステップで行われます。表 1 は、Amazon* C5n インスタンスで行われたさまざまなシミュレーションに関するいくつかの情報を示しています。
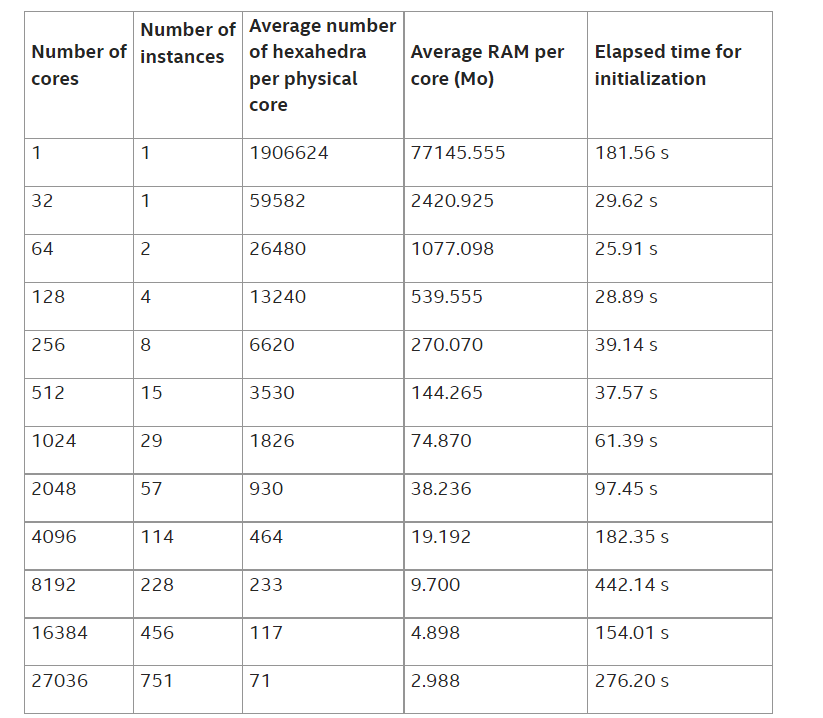
表 1: c5n.18xlarge インスタンスで行われたシミュレーションについての情報
以下の表 (表 2、表 3、表 4、表 5) は、C5n および M5zn インスタンスにおける EFISPEC3D の強力なスケーリング性を示しています。
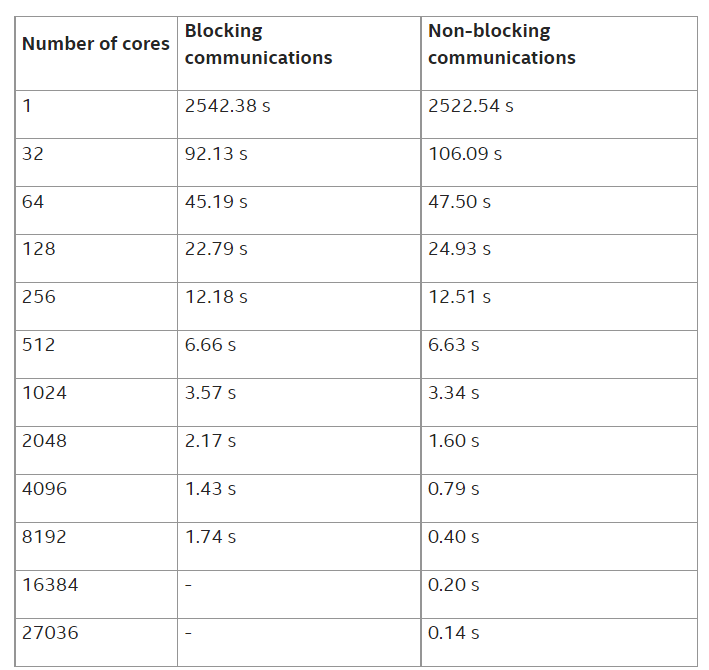
表 2: c5n.18xlarge インスタンスでの時間ループ計算の経過時間 (秒)
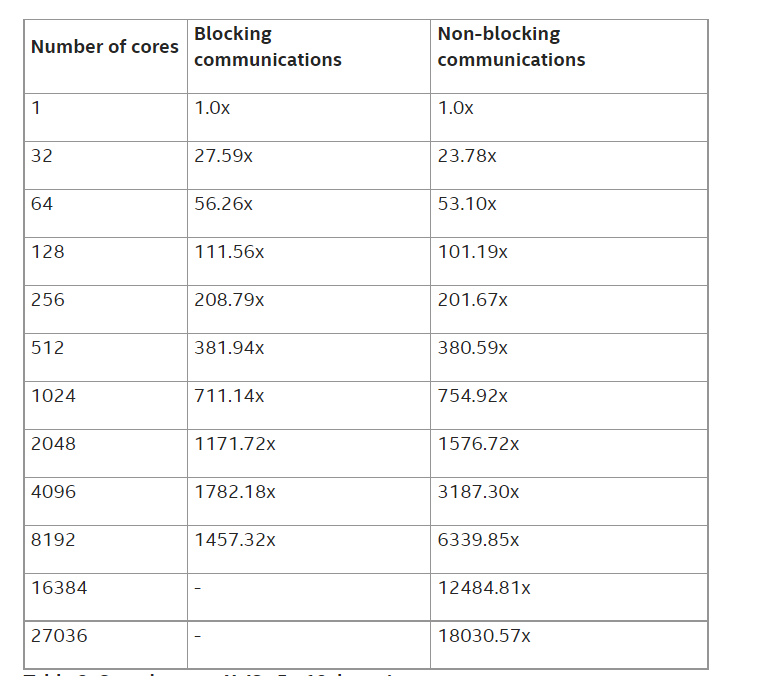
表 3: c5n.18xlarge インスタンスでの高速化率
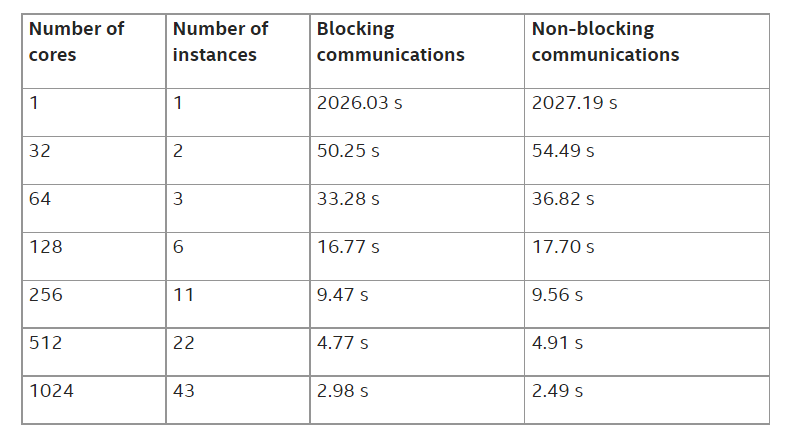
表 4: m5zn.12xlarge インスタンスでの時間ループ計算の経過時間 (秒)
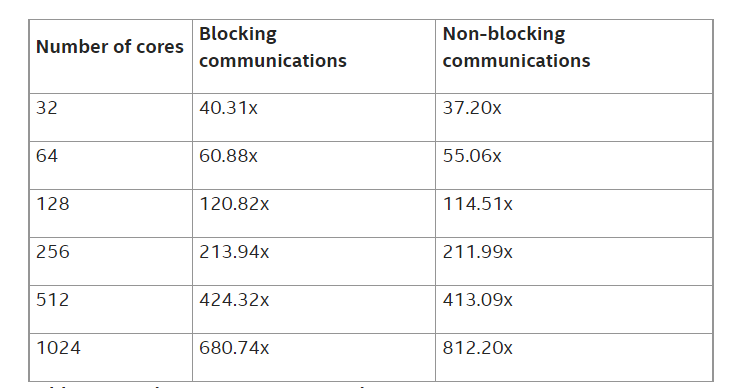
表 5: m5zn.12xlarge インスタンスでの高速化率
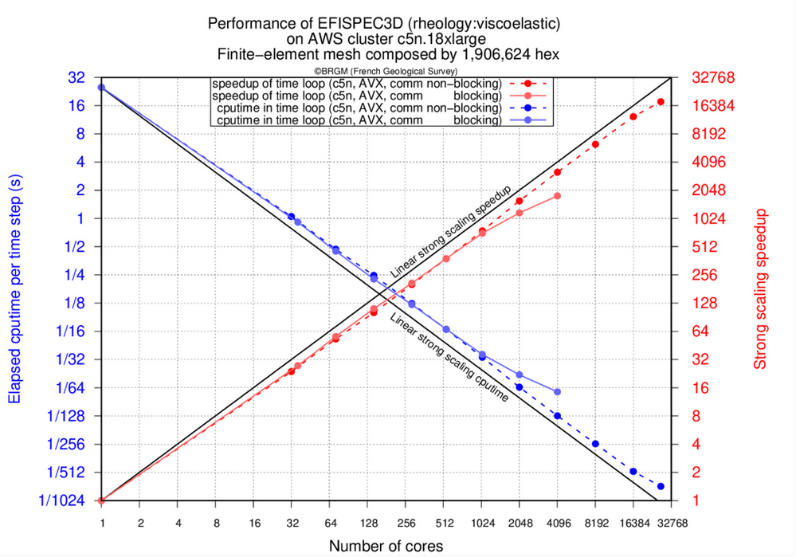
図 1: c5n.18xlarge インスタンスでの強力なスケーリング
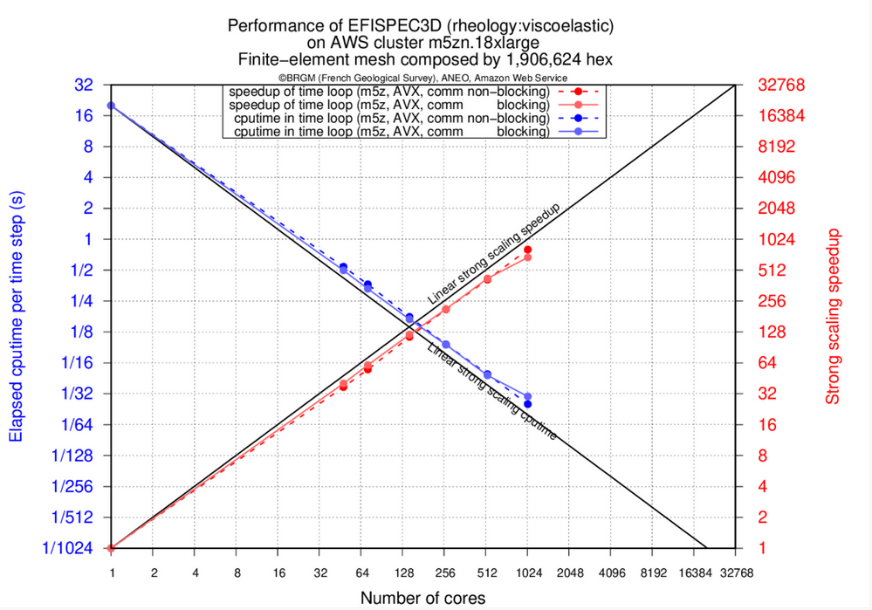
図 2: m5zn.12xlarge インスタンスでの強力なスケーリング
EFISPEC3D の時間ループ計算の経過時間 (秒) と、単一物理コアでのシミュレーションに対する高速化の結果を示しています。EFA を用いた AWS* クラスターでは、27036 コアで 67% の高速化を達成し、特にノンブロッキング通信バージョンでは 27036 物理コアで 18030 の高速化を達成しました (図 1 参照)。このような高速化により、標準的な地震シミュレーションの場合、シングルコアで 300 日かかるところを 25 分程度で計算できるようになります。
ブロッキング通信を使用した場合、MPI 呼び出しの送受信時間が圧縮できないため、2048 コアあたりで性能低下が見られます。通信と計算をオーバーラップすることで、27036 コアまで性能の低下を抑えることができます。
7M 六面体シミュレーション
この 2 回目の実験では、EFISPEC3D アプリケーションでインテル® MPI ライブラリーによるデータ書き込みを利用しているため、Amazon* FSx for Lustre ファイルシステムへの読み込みと書き込みを可能にしました。そして、Amazon* FSx for Lustre のパフォーマンスを確認することにしました。
2048 個のタスクが同時にファイルシステムに結果を書き込む場合の性能をテストすることが目的です。このテストでは、57 台の c5n.18xlarge インスタンス (合計 2052 コア) からなるクラスターを使用しました。
アプリケーションの実行により、2TB のデータが生成され、そのほとんどが 1 つのファイルに凝縮されます。ファイルシステムの性能構成は、ブロックサイズ係数とストライピング係数の 2 つの主要なパラメーターに基づいています。これらはそれぞれ、アプリケーションによって同時に書き込まれるデータ・パケット・サイズとパケット数です。このファイルシステムの設定により、アプリケーションの書き込みサイズとファイルシステムが許可する書き込み行数に応じて、最適なディスクへの書き込みのキャリブレーションが可能となります。
複数のファイルシステム構成で性能分析ができるように、ファイルサイズを 206GB に縮小しました。この手順により、得られた性能結果の信頼性を維持したまま、Amazon* FSx for Lustre ファイルシステムのより多くの異なる構成を評価することができました。
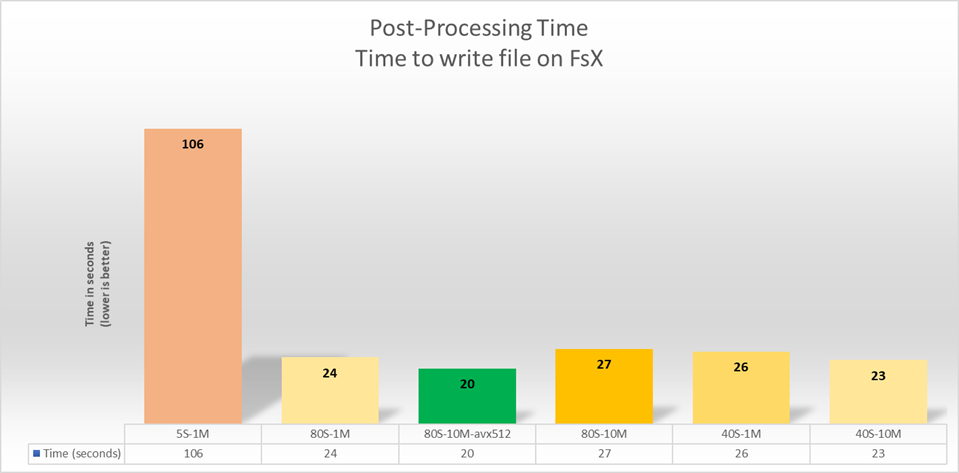
図 3: Amazon* FSx for Lustre の MPI によるファイル書き込みのパフォーマンス
データ (206GB) の読み込みフェーズで測定された帯域幅に対するファイルシステムのパラメーター Lustre の影響を示しています。ストライプサイズは 1MB から 10MB まで、ストライピング係数は 5 から 80 まで変化します。
図 3 では、Amazon* FSx for Lustre のパラメーターを変えて、1 回ずつ実行したことを表しています。例えば、5S – 1M は、ストライピング係数 5、データのブロックサイズ 1MB でテストがキャリブレーションされたことを意味します。
これらのテストは、96TiB の FSx for Lustre ボリュームと 80 個の OSD を使用して実行されました。「Scratch 2」デプロイメント・タイプまたは FSx for Lustre が使用されました。この FS は、1TB あたり 200MBs の理論性能と 1.3GB/s のバースト帯域幅を提供します。デプロイされたファイルシステムのベースライン性能は 16GB/s で、バースト性能は 104GB/s でした。
この 6 回の実行の結果、EFISPEC3D では、ファイルシステムをストライピング係数 80、ブロックサイズ 10MB に設定した場合に、最高の性能を発揮することがわかりました。
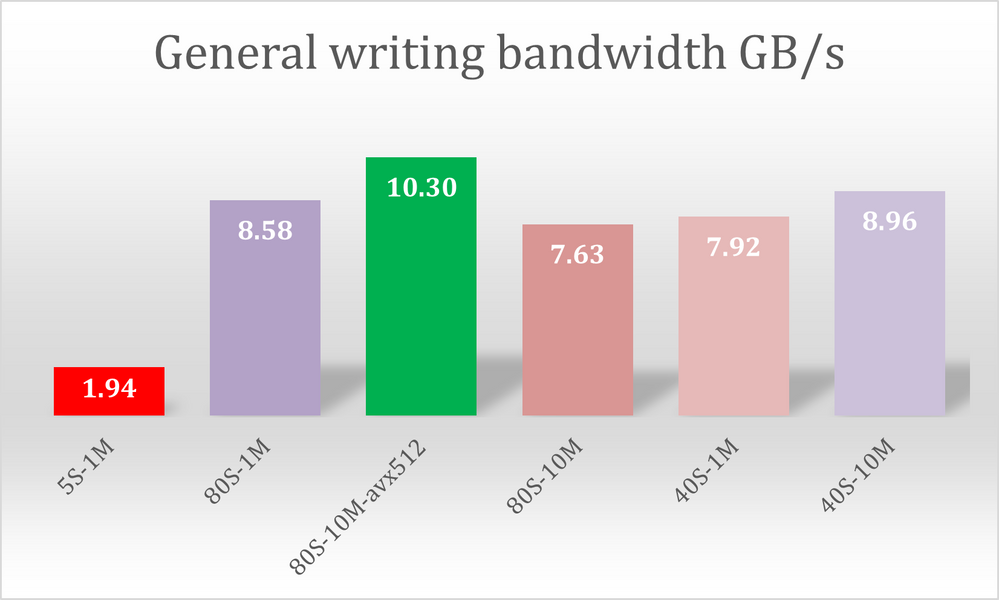
図 4: ポスト処理段階でのファイル書き込みにかかる一般的な帯域 (ギガバイト/秒)
EFISPEC3D アプリケーションの後処理のフェーズでは、206GB の結果ファイルを書き込むために帯域幅が 10.3GB/s まで上昇しました。
パブリックコスト調査から 7M 実行
7 メガ六面体のシミュレーションにおいて、米国バージニア州で提案された AWS* のパブリック価格をもとに EFISPEC3D アプリケーションの実行コストを調査しました。
注意点として、選択したインフラは、2048 個の物理コアを持つ c5n.18xlarge インスタンスと、72 個の vCPU を持つインテル® Xeon® Platinium プロセッサーをベースにしています。これは、同じリージョン、つまり us-east-1 リージョンで 57 台の c5n.18xlarge インスタンスを起動できたことを意味します。
また、FSx ファイルシステムは、1 クラスターあたり 1 日 30 ドル、3.6TB のストレージを使用します。
このタイプの実行にかかるクラスターのコストは、c5n.18xlarge の 57 インスタンスを使用して 25 分間にアプリケーションを実行した場合、合計で 123 ドルのパブリック価格となります。
まとめ
研究開発とベンチマークの段階では、AWS* がサポートするオープンソースのクラスター管理ツール「AWS ParallelCluster」を使って、HPC 環境の導入、インストールおよび設定がいかに簡単にできるかを確認することができました。また、C5n インスタンスが世界中のすべての AWS* リージョンで迅速に利用できるようになったことも確認されています。M5zn インスタンスは、さまざまな点で大きく異なってきます。より高速なコアが少なく、インテル® アーキテクチャー開発コード名 Cascade Lake をベースにしています。AWS* では 400 種類以上のインスタンスが利用可能です。HPC アプリケーションと同様に、実際のアプリケーションとデータをテストして、どのシステムがどのアプリケーションに最適なコスト・パフォーマンスを提供するか確認することに代わるものはありません。
強力なスケーリング・テストでは、EFISPEC3D アプリケーションの非常に優れたパフォーマンスを観察することができ、HPC の世界における C5n および M5zn サーバーの力を実証することができました。
Amazon* FSx for Lustre ファイルシステムに関しては、10GB/s 以上の帯域幅を達成し、すべての計算ノードによる集中的なディスク書き込みを伴うアプリケーションの要件を十分満たすことができました。
EFISPEC3D は、HPC ワークショップで紹介されています。このワークショップでは、HPC クラスターの導入と EFISPEC3D ソフトウェアの実行のプロセスをガイドしています。こちらのページ (英語) でご覧いただけます。
法務上の注意書き
製品および性能に関する情報
性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
注意事項の改訂 #20201201
性能の測定結果は記事執筆時点のテストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。構成の詳細は、補足資料を参照してください。絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
実際の費用と結果は異なる場合があります。
インテルは、サードパーティーのデータについて管理や監査を行っていません。ほかの情報も参考にして、データが正確かどうかを確認してください。
インテルのテクノロジーを使用するには、対応したハードウェア、ソフトウェア、またはサービスの有効化が必要となる場合があります。
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
脚注
[1] De Martin, F. (2011). Verification of a spectral-element method code for the Southern California Earthquake Center LOH. 3 viscoelastic case. Bulletin of the Seismological Society of America, 101(6), 2855-2865.
Sochala, P., De Martin, F., & Le Maitre, O. (2020). Model Reduction for Large-Scale Earthquake Simulation in an Uncertain 3D Medium. International Journal for Uncertainty Quantification, 10(2).
De Martin, F., Chaljub, E., Thierry, P., Sochala, P., Dupros, F., Maufroy, E., … & Hollender, F. (2021). Influential parameters on 3-D synthetic ground motions in a sedimentary basin derived from global sensitivity analysis. Geophysical Journal International, 227(3), 1795-1817.
[2] An Elastic Fabric Adapter (EFA) is a network device that you can attach to your Amazon EC2 instance to accelerate High Performance Computing (HPC) and machine learning applications. EFA enables you to achieve the application performance of an on-premises HPC cluster, with the scalability, flexibility, and elasticity provided by the AWS Cloud.