

Netflix と GE Healthcare は最近、ライブラリー、フレームワーク、ツールで構成されるインテル・ソフトウェアの豊富なポートフォリオが、ヘルスケアからメディアまで幅広い分野において、パフォーマンスと開発者の生産性を向上し、重要なビジネス課題を解決した事例を紹介しました。
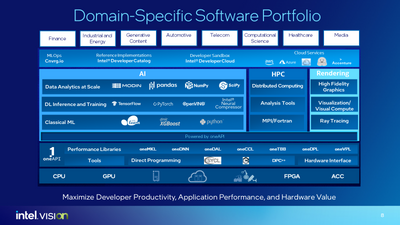
最新のインテル・ソフトウェアを使用すると、アクセラレーターを内蔵した CPU から、CPU、GPU、FPGA、その他のアクセラレーターを搭載したマルチアーキテクチャー・システムに至るまで、インテル・ハードウェアで最高のパフォーマンスを実現できます。例えば、TensorFlow* (英語) や PyTorch* (英語) から scikit-learn* や pandas (英語) まで、いくつかの業界標準フレームワークのインテル拡張を使用することで、開発者はたった 1 行のコード変更で AI アプリケーションのパフォーマンスを 10 倍以上向上 (英語) できます。
インテルはまた、これらのフレームワークのデフォルトのバージョンに定期的に最適化をアップストリームしています。ストリーミング・メディア・サービス会社の場合、ソフトウェア AI アクセラレーターによりパフォーマンスが 10 倍向上することで、月あたりおよそ数百万ドルのコスト削減につながる可能性があります1。
Netflix のシニア・パフォーマンス・エンジニアの Amer Ather (英語) 氏は、この点について、次のように述べています。
「パフォーマンス・エンジニアリング・チームの使命は、Netflix ストリーミング・ビジネスを管理するクラウド・インフラストラクチャーのコストを削減するため、Netflix ストリーミング環境に高いレベルの効率をもたらすことです。これは、アクティブなベンチマーク、プロトタイプのパフォーマンス強化、およびパフォーマンス・ツールの構築によって達成されます。
Netflix は、世界中の 2 億 3,000 万人を超える有料加入者にプレミアム・ストリーミング・サービスを提供しています。加入者は、アプリケーションが高速で、応答性が高く、効率的であることを期待しています。Netflix アプリケーションはさまざまなユーザーデバイスでホストされており、それぞれに独自の要件があります。これらのデバイスは、さまざまなネットワーク条件下で動作します。したがって、190 カ国の加入者に高品質のコンテンツを配信するには、パフォーマンスの最適化とエンドツーエンドの信頼性が不可欠です。
ストリーミング・パイプラインは 3 段階のプロセスです。ソースアセットをダウンサンプリングし、それをエンコードし、エンコードされたビデオをエンドデバイスへ送信します。エンドデバイスは、受け取ったビデオのデコードとアップサンプリングを行いデバイスで再生します。最近、Netflix は最適なストリーミング ビデオ品質を実現するため、強力なインテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) を利用したビデオ・ダウンスケーリング用のニューラル・ネットワークを採用しました。」
詳細は、Ather 氏のプレゼンテーションの要約 (英語) を参照してください。
このような高速コンピューティング技術が企業に浸透するにつれて、GPU、FPGA、特殊 AI ASIC、さらにはアクセラレーター内蔵 CPU (英語) など、アクセラレーター・ハードウェアの多様性が増大しています。

新しいアクセラレーター・アーキテクチャーが爆発的に増えたことで、ソフトウェア・チームは多くの課題に直面しています。異なるアーキテクチャーは通常、独自の言語、ツール、ライブラリーを必要とし、開発者にとってコストと時間のかかる複雑さを生み出します。また、コードの再利用も制限されます。さらに、このアプローチはベンダーへの依存を助長します。その結果、ハードウェアの選択肢がソフトウェアによって制限されます。
この連鎖を断ち切るため、インテルは oneAPI (英語) 業界イニシアチブをサポートしています。Khronos Group が提供する、広く使用されている C++ 言語のオープンで標準ベースの拡張である SYCL* を活用することで、oneAPI は開発者が CPU、GPU、FPGA、その他のアクセラレーター向けにプログラミングできるようにします。
GE Healthcare のコンピュート担当チーフエンジニアの Evgeny Drapkin 氏は、チームがインテル® oneAPI ツールを活用して複雑な医療機器のパフォーマンスを向上し、レガシーコードを SYCL* に移行してマルチアーキテクチャー・プログラミングを簡素化した方法を紹介しています。
ビデオ (英語) の中で Drapkin 氏は次のように述べています。
「oneAPI でインテルのチームと協力できることを本当にうれしく思っています。oneAPI にはさまざまな潜在的なメリットがあり、レガシーコードを C++ から oneAPI に移行すれば、すぐにマルチコアのインテル® CPUを利用できます。また、レガシーコードを GPU 対応にすることもできます。ターゲットが異なるだけの全く同じコードを、インテル® CPU、インテル® GPU、および他のベンダーの GPU で実行できることは、oneAPI が移植性に優れていることを示しています。これは、oneAPI の大きな利点であることは間違いありません。そして、これは最小限の労力で実現することができます。
oneAPI、特にインテル® oneDNN ライブラリーの興味深い使用例として、AI とディープラーニングの推論/トレーニングの畳み込み演算を高速化する専用の固定関数ハードウェアをプログラムできることが挙げられます。cuDNN コードをインテル® oneDNN に移行する方法を学ぶことは、我々にとって非常にエキサイティングなことでした。cuDNN からインテル® oneDNN にコードを移行すると、インテル® GPU で実行できるようになります。AI やディープラーニングの推論を高速化するため、今後も多くのコードを移行することになると考えています。
我々は、oneAPI はヘテロジニアス計算システムをプログラミングする業界標準となる可能性があると見ており、oneAPI を使用することで、複数のアーキテクチャーや複数のベンダーにコードを移行できるようになり、あるプログラミング・モデルから別のプログラミング・モデルへとコードを完全に書き直さなければならない場合に生じる数百万ドルの構成コストと、何年もかかるエンジニアリングの労力を軽減できる可能性があると信じています。」
インテル® oneAPI とインテルの AI ツール (英語) を使用して、最新のインテル製ハードウェアのパフォーマンスを最大限に引き出し、多様なアクセラレーター・アーキテクチャーを活用する方法と、一般的な AI フレームワーク (英語) のインテルの最適化によりドロップインでパフォーマンスを向上する方法については、インテルのサイトにある以下の記事を参照してください。
1 ソフトウェア AI アクセラレーターで最大 100 倍のパフォーマンス向上を達成 (英語)
インテル® oneAPI ツールキット
有償サポート製品はこちら
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
SYCL は Khronos Group の商標です。