

この記事は、インテル® デベロッパー・ゾーンに公開されている「PyTorch* 2.4 Debuts with Initial Support of Intel® GPUs to Accelerate AI Workloads」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

PyTorch* 2.4 では、インテル® データセンター GPU マックス・シリーズの初期サポート1 が提供され、インテル® GPU と SYCL* ソフトウェア・スタックが公式の PyTorch* スタックに追加され、AI ワークロードのさらなる高速化に役立ちます。
1 GPU サポートとパフォーマンス向上のため、PyTorch* 向けインテル® エクステンション (英語) をインストールすることを推奨します。
利点
インテル® GPU のサポートにより、ユーザーは GPU の選択肢が増え、フロントエンドとバックエンドの両方で一貫した GPU プログラミング・パラダイムを利用できます。最小限のコーディング作業で、インテル® GPU でワークロードを実行し、デプロイすることが可能です。この実装では、ストリーミング・デバイスに対応するため、PyTorch* デバイスとランタイム (デバイス、ストリーム、イベント、ジェネレーター、アロケーター、ガード) を一般化しています。この一般化により、ユビキタス・ハードウェアへの PyTorch* のデプロイが容易になるだけでなく、さまざまなハードウェア・バックエンドの統合も容易になります。
インテル® GPU ユーザーは、組込み PyTorch*、統合されたソフトウェア配布、一貫した製品リリース時期により継続的なソフトウェア・サポートを直接利用し、より優れた経験が得られます。
インテル® GPU サポートの概要
PyTorch* にアップストリームされたインテル® GPU サポートは、PyTorch* 組込みフロントエンドで Eager モードとグラフモードをサポートします。Eager モードでは、よく使用される Aten 演算子が SYCL* プログラミング言語で実装されました。最もパフォーマンスが重要なグラフと演算子は、oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (oneDNN) と oneAPI マス・カーネル・ライブラリー (oneMKL) を使用して高度に最適化されています。グラフモード (torch.compile) では、インテル® GPU 向けの最適化を実装し Triton を統合するため、インテル® GPU バックエンドが有効になりました。
PyTorch* 2.4 では、Aten 演算子、oneDNN、Triton、インテル® GPU ソースビルド、インテル® GPU ツールチェーン統合など、インテル® GPU サポートの重要なコンポーネントが追加されました。一方、PyTorch* Profiler(Kineto と oneMKL の統合に基づく) は、次の PyTorch* 2.5 リリースで実装するべく現在開発中です。図 1 は、PyTorch* にアップストリーム済みおよび今後アップストリーム予定のインテル® GPU のフロントエンドとバックエンドの改善を示しています。
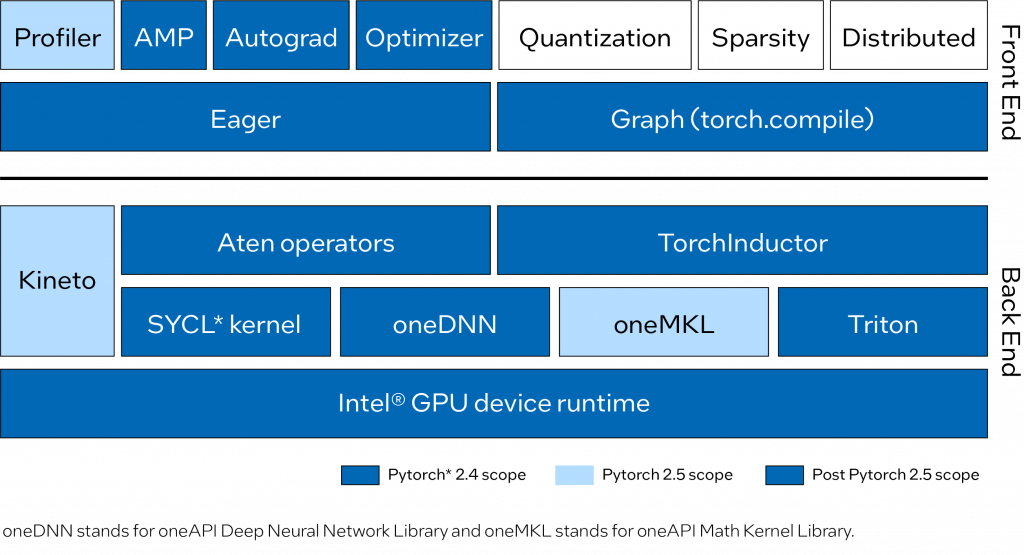
機能
トレーニングと推論のため、インテル® データセンター GPU マックス・シリーズの主要な機能を提供するだけでなく、Linux* 上の PyTorch* 2.4 リリースは、PyTorch* がサポートする他のハードウェアと同じユーザー体験を提供します。そのため、CUDA* からコードを移行する場合、コード中のデバイス名を cuda から xpu に変更するだけで、既存のアプリケーション・コードをインテル® GPU 上で実行できます。以下に例を示します。
# CUDA* コード
tensor = torch.tensor([1.0, 2.0]).to("cuda")
# インテル(R) GPU 用のコード
tensor = torch.tensor([1.0, 2.0]).to("xpu")インテル® GPU では PyTorch* 2.4 の次の機能を利用できます。
- トレーニングと推論ワークフロー。
torch.compileと Eager の基本関数の両方がサポートされており、Eager モードとコンパイルモードの Dynamo Hugging Face* ベンチマークを完全に実行します。- FP32、BF16、FP16、自動混合精度 (AMP) などのデータ型。
- Linux* とインテル® データセンター GPU マックス・シリーズ上で動作します。
使用方法
- インテル® データセンター GPU マックス・シリーズは、インテル® Tiber™ デベロッパー・クラウドで試すことができます。
- 環境のセットアップ、ソースのビルド、およびサンプルについては、こちら (英語) を参照してください。
- インテル® Tiber™ デベロッパー・クラウドの登録手順については、こちらを参照してください。アカウントを作成後、以下の操作を行ってください。
- インテル® Tiber™ デベロッパー・クラウド (英語) にサインインします。
- Training (英語) セクションから、PyTorch 2.4 on Intel® GPUs ノートブックを開きます。
- ノートブックで PyTorch 2.4 カーネルが選択されていることを確認します。
エクセルソフトでは、インテル® Tiber™ デベロッパー・クラウドの評価用クーポンを配布しています。ご興味のある方は、こちらのフォームよりお問い合わせください。
まとめ
PyTorch* 2.4 のインテル® GPU サポートは、初期サポート (プロトタイプ・リリース) であり、AI ワークロードを高速化するため、インテル® データセンター GPU マックス・シリーズのインテル® GPU を初めて PyTorch* エコシステムに導入します。
PyTorch* 2.5 リリースでベータ品質に到達できるよう、インテル® GPU サポートの機能とパフォーマンスを継続的に強化しています。製品開発がさらに進んだら、インテルのクライアント GPU は AI PC 使用シナリオの GPU サポートリストに追加される予定です。また、PyTorch* 2.5 では、次のような機能も検討しています。
- Eager モード: より多くの Aten 演算子を実装し、Dynamo Torchbench と TIMM Eager モードを完全に実行します。
- Torch.compile: パフォーマンスと引き換えに Dynamo Torchbench と TIMM ベンチマーク・コンパイル・モードを完全に実行します。
- プロファイラーとユーティリティー: torch.profile を有効にしてインテル® GPU をサポートします。
- PyPI wheel ディストリビューション。
- Windows* とインテルのクライアント GPU シリーズのサポート。
コミュニティーによる PyTorch* のインテル® GPU サポート (英語) への新しい貢献の評価を歓迎します。
関連情報
謝辞
PyTorch* オープンソース・コミュニティーの技術議論と洞察に感謝します: Nikita Shulga、Jason Ansel、Andrey Talman、Alban Desmaison、Bin Bao。
また、PyTorch* チームのプロフェッショナル・サポートと指導にも感謝します。
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
日本語での優先サポートのご案内
エクセルソフトは、インテル® ソフトウェア開発ツールの正規販売代理店として、25 年以上にわたって国内の開発者向けに日本語で技術サポートや最新情報を提供してきました。インテルとの長年の強固なパートナーシップを通して、国内に存在する多くの企業、研究機関、学術機関でのツールの導入やプログラムの最適化に携わってきた経験を活かし、国内の開発者や企業によるクラウドの導入を促進するだけでなく、インテル開発ツールを活用してクラウド環境でも高速でオープンな開発を実現するためのお手伝いをします。