

この記事は、インテルのブログで公開されている「Develop Highly Optimized Applications Faster with Compiler Optimization Reports」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
インテル® oneAPI 2025.0 でさらに詳細になった最適化レポート
インテル® oneAPI DPC++/C++ コンパイラーとインテル® Fortran コンパイラーはどちらも、ソースコードに対してコンパイラーが実行した (または実行しなかった) 重要な最適化を説明するレポートを提供します。
これにより開発者は、コードの作成、コンパイル、テスト中に、コードとコンパイラーによる最適化の影響について、即座にフィードバックを得ることができます。つまり、ソフトウェア開発サイクルを加速し、アプリケーションのパフォーマンス目標をより早く達成するのに役立ちます。
バージョン 2025.0 に含まれる最新のコンパイラー・リリースでは、インテルは最適化レポートの品質と詳細レベルのさらなる改善に注力しました。これにより、インテル® C++ コンパイラーとインテル® Fortran コンパイラー・クラシックが提供するレポートとのギャップを解消しました。また、お客様からのフィードバックと機能要望を精査し、多くの新機能を追加しました。多くのご意見とご提案をありがとうございました。この記事では、最も重要な変更点について概説します。
まず、コンパイラー最適化レポートの基本的な使用モデルを再確認してみましょう。
最適化レポートの基本
最適化レポートは、最適化に関するガイダンスと、最適化が適用された理由、または適用されなかった理由を示す 3 種類のリマークを提供します。
- 正常に実行された最適化
- 何らかの理由で失敗した最適化
- 成功した最適化と失敗した最適化の両方に関する詳細情報
以下の例の説明:
- 緑色のリマーク (#25436) は、最適化が成功したことを示します。
- 赤色のリマーク (#15344) は、最適化が実行されなかったことを示します。
- 青色のリマーク (#15346) は、最適化が実行されなかった理由を詳しく説明します。
この情報は、パフォーマンスを向上するためソースコードを変更するのに役立つかもしれません (分かりやすくするために色分けしていますが、最適化レポートでは色分けされていません)。

最適化レポートを生成する理由はいくつかあります。前述ように、コードの実行速度が予想よりも遅く、その理由を把握したい場合、最適化レポートを確認すれば、インテル® VTune™ プロファイラーなどのパフォーマンス解析ツールに頼らなくても、すぐに原因を見つけることができます。
情報の種類
例えば、コンパイラーが特定のループをベクトル化しなかった理由を知ることで、コンパイラーがその最適化を実行できるようにコードを書き直す方法を理解するのに役立ちます。コードをさまざまな方法で記述し、最適化レポートを比較することで、「コンパイラーのように考える」方法を学び、結果を改善できます。また、コンパイラーが最適に動作していない可能性があると判断した場合は、コンパイラーのバグレポートを送信することもできます。
最適化レポートを使用して、さまざまなコンパイラーがコードを処理する方法を比較できます。インテル® コンパイラー・クラシックも最適化レポートを提供するため、コンパイラー・クラシックからインテル® oneAPI コンパイラーに移行したことでコードのパフォーマンスが向上または低下した場合、両方のコンパイラーから最適化レポートを生成して、明確な原因があるかどうかを確認できます。
最適化レポートは、プログラムのビルディング・ブロックを中心に構成されます。図 1 に示すように、リマークは関数、ループ、OpenMP* 作業領域ごとにグループ化されます。
ソースの位置情報 (ファイル、行、列) は、ループや作業領域がコード内のどこにあるかを特定するのに役立ちます。可能な限り、これらのビルディング・ブロックは最適化レポートの各セクション内でソース順に表示されますが、最適化によってこれが複雑になることがあります。
積極的なループ最適化では、ループの削除、新しいループの導入、ループの順序の変更、ループの融合または分割などが行われます。最適化レポートには、これらの変換後の新しいループ構造が反映されますが、元のループの場所を特定するソースの位置情報も存在し、ループが削除、導入、またはその他の方法で変換されたことを説明するリマークが挿入されます。
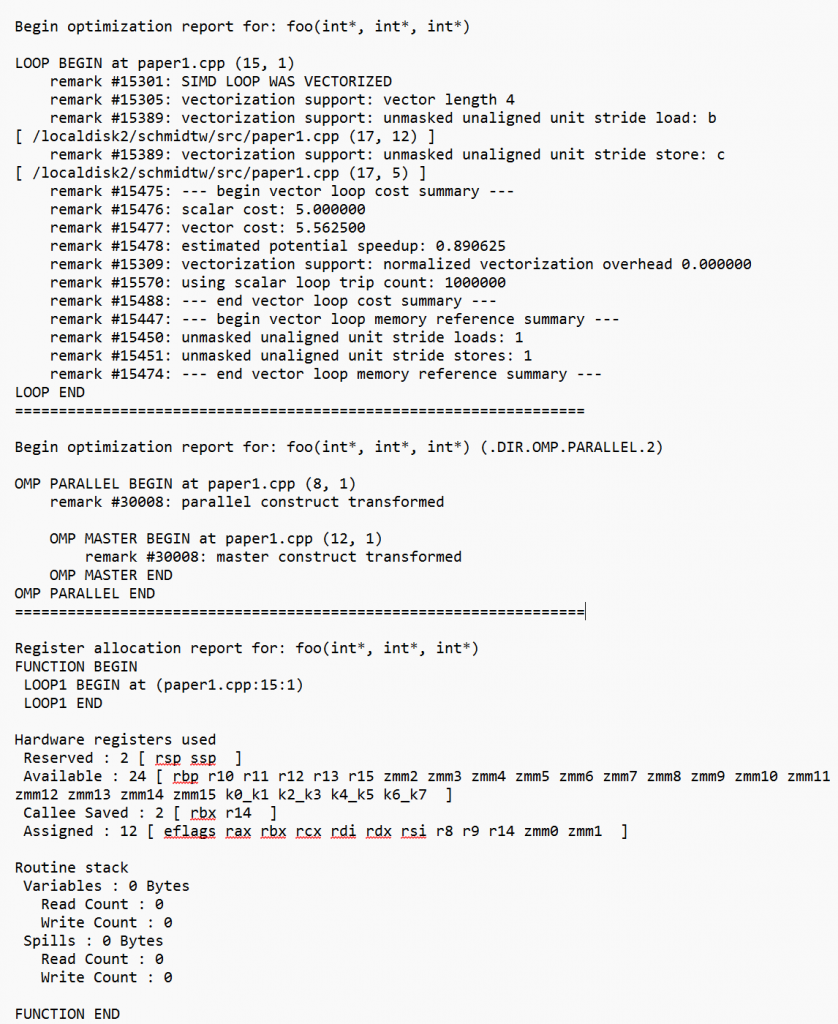
図 1: 典型的な最適化レポートのレイアウト
モジュールレベル (およびリンク時の最適化がある場合はプログラム全体レベル) では、インライン展開レポートがあり、関数のクローン作成などのインライン展開やその他のプロシージャ間の最適化によってコードの関数構造がどのように変更されたかを追跡するのに役立ちます。また、インストルメントまたはサンプリングされたプロファイル (「ハードウェア PGO」) によって生成されるプロファイルに基づく最適化レポートもあります。GPU や FPGA などの特殊なハードウェアを使用して高速計算を行う場合、オフロードされた計算に対して個別の最適化レポートが生成されます。
レポートの生成
最適化レポートを生成するには、コンパイル・コマンドラインに -qopt-report (Linux*) または /Qopt-report (Windows*) を追加するだけです。オプションで、レポートの「詳細レベル」を指定するには、「=N」を追加します。ここで、N は 0 から 3 までの値です。レベルが上がるごとに、より多くのリマークが表示されます。一般的な目安は次のとおりです。
- N = 0: 最適化レポートなし (あまり役に立ちません)
- N = 1: 成功した最適化に関するリマークを含みます
- N = 2: 1 + 失敗した最適化に関するリマークを含みます (デフォルト)
- N = 3: 2 + 詳細な説明のリマークを含みます
以下は、Linux* コマンドラインの例です。
icpx -c -O3 -qopt-report=2 myfile.cpp
ifx -c -O3 -qopt-report=3 myfile.f90以下は、同等の Windows* コマンドラインの例です。
icpx -c -O3 /Qopt-report=2 myfile.cpp
ifx -c -O3 /Qopt-report=3 myfile.f90これらのコマンドは、デフォルトで myfile.optrpt という名前のファイルを生成します。必要に応じて、-qopt-report-file (Linux*) または /Qopt-report-file (Windows*) オプションを使用して名前を変更 (または出力をストリームにリダイレクト) できます。詳細は、コンパイラーのドキュメントを参照してください。
バージョン 2025.0 の変更点
この背景を踏まえて、バージョン 2025.0 で導入された変更点を詳しく見ていきましょう。
新しいオプション
インテル® oneAPI コンパイラーは、インテル® コンパイラー・クラシックで利用可能な -qopt-report-phase=xxx (Linux*) および /Qopt-report-phase=xxx (Windows*) オプションをサポートしました。このオプションを使用すると、関心のある領域に注目した小さなレポートを生成できます。xxx には、以下の値を指定できます。
| フェーズ | 動作 |
|---|---|
| cg | コード生成レポートのみ表示します。 |
| ipo | プロシージャー間の最適化レポートのみ表示します。 |
| loop | ループ最適化レポートのみ表示します。 |
| openmp | OpenMP* 作業領域レポートのみ表示します。 |
| pgo | プロファイルに基づく最適化レポートのみ表示します。 |
| vec | ベクトル化レポートのみ表示します。 |
| all | すべてのレポートを表示します (デフォルト)。 |
複数の値をカンマ区切りのリストで指定することもできます。以下に例を示します。
ifx -c -O3 -qopt-report=3 -qopt-report-phase=loop,vec myfile.f90インテル® oneAPI コンパイラーで利用できるようになったもう 1 つのインテル® コンパイラー・クラシックのオプションは、‑qopt-report-names (Linux*) および /Qopt-report-names (Windows*) です。これにより、最適化レポートで関数/メソッドの「マングル名」と「非マングル名」のどちらを表示するかを選択できます。C++ には関数のオーバーロードがあるため、関数名の完全な指定にはシグネチャー表現を含める必要があります。マングル名は、シグネチャーを文字列でエンコードします。マングル名はアセンブリー・リストにあるため、アセンブリー・リストと一致させる場合は、-qopt-report-names=mangled (Linux*) または /Qopt-report-names=mangled を使用します。これにより、以下のような出力が生成されます。
Begin optimization report for : _ZN6matrix4readEii代わりに、ソースコードと一致させる場合は、デフォルトの -qopt-report-names=unmangled (Linux*) または -qopt-report-names=unmangled (Windows* )を使用します。同じ関数が以下のように表示されます。
Begin optimization report for : matrix::read(int, int)Fortran 関数名もこのオプションによって変更されますが、大きく変わりません。
インフラストラクチャーの改善
以前のリリースでは、-qopt-report (Linux*) または /Qqopt-report (Windows*) を指定すると、インテルの最適化レポートに加えて、LLVM の最適化レポートも生成されました。これは、.yaml 拡張子の大きなファイルとして表示される場合もあります。LLVM の最適化レポートはバイナリー形式で生成されるため、人間が可読可能な形式で表示するには、別途 opt-viewer.py ツールが必要です。さらに、LLVM の最適化レポートは非常に冗長で、生成にはかなりのコンパイル時間を要し、コンパイラー開発者が使用することを目的としているため、インテル® コンパイラーのユーザーには使用を推奨していません。したがって、-qopt-report (Linux*) または /Qopt-report (Windows*) を指定しても、LLVM の最適化レポートは生成されなくなりました。このレポートを取得したい場合は、-fsave-optimization-record オプションを使用してください。
最適化レポートは、デバッグに便利な -O0 (Linux*) または /O0 (Windows*) オプションで使用できるようになりました。最後に、最適化レポートのインフラストラクチャーは、複雑な最適化を含むプログラムセクション (関数、ループ、作業領域) の順序をより適切にサポートするため、現在改良中です。インフラストラクチャーの制限により、レポートでセクションが分かりづらい順序で表示されることがありましたが、改良により、一見矛盾しているように見える順序でセクションが表示されることは減少すると予想されます。この作業は進行中であり、バージョン 2025.1 で実装予定です。
インライン展開レポートと PGO レポートの改善
プロファイルに基づく最適化 (PGO) レポートが大幅に改善され、従来のコンパイラー・レポートと同等のデータが生成されるようになりました。インストルメントされた PGO によって生成されたデータが利用できる場合、最適化レポートには、各関数について次の情報が含まれます。
- データが適用された
- データが見つからなかったためデータが適用されなかった
- データが収集されてから関数が変更されたためデータが適用されなかった
ハードウェア PGO によって生成されたデータが利用できる場合、最適化レポートには、データが適用された関数の情報が含まれます。さらに、プロファイルの使用状況に基づいて「ホット」および「コールド」と見なされる関数の情報と、特定の呼び出しターゲットに特化した間接関数呼び出しの情報が含まれます。
インライン展開レポートは、Thin LTO モード (プログラム全体の最適化を実行しながら並列コンパイルを可能にする) で適切に動作するようになり、1 つのコンパイルのデータが別のコンパイルのデータによって上書きされることがなくなりました。また、ユーザーから報告された、出力の順序に関連するバグもいくつか修正しました。
ループ最適化レポートの改善
ループ・オプティマイザーは、最適化によって完全に排除されたループも含め、各ループについてリマークを生成するようになりました。このリマークを保持するため、レポートにプレースホルダー「loop」が表示され、他のループに対するその相対位置が改善されました。
ループ・オプティマイザーは、ユーザーが変更を加えることでパフォーマンスを改善できると考えられる状況を検出し、最適化レポートにリマークを追加します。例えば、ループ・オプティマイザーは、ループ交換の最適化が有益である可能性を認識できます。ただし、ソースでループの入れ子が「完全」ではないと (異なるループ間にソース・ステートメントがあると)、コンパイラーはこれを自動的に実行しない可能性があります。最適化レポートはこのシナリオに検出して、ソースを書き直して入れ子内の誘導変数の順序を交換することで、ユーザーがパフォーマンスを改善できる可能性があることを示すことができます。
subroutine compute(a,b,c,d,n)
real*8 a(n,n)
real*8 b(n,n)
real*8 c(n,n)
real*8 d(n,n)
do k=1,n
do j=1,n
if (j.lt.k) d(k,j) = d(j,k)
do i=j,n
c(j,i) = c(j,i) + a(i,k) * b(k,j)
enddo
enddo
enddo
end subroutine 図 2: 最適化に影響する入れ子のループ
例として、図 2 の Fortran コードを考えてみましょう。プログラマーは、おそらくループを 2 セット持つよりも効率的だと考えて、関連のない 2 つの計算を同じループの入れ子内に配置したのでしょう。次のようにコードをコンパイルするとします。
ifx -c -xAVX2 -qopt-report=3 paper2.f90 -qopt-report-phase=loop最適化レポートには、次のようなリマークが含まれます。
LOOP BEGIN at paper2.f90 (6, 7)
remark #25445: Loop interchange not done due to: non-perfect loopnest
remark #25451: Advice: Loop interchange, if possible, might help loopnest.
Suggested Permutation: ( 1 2 3 ) --> ( 3 2 1 )これは、最も外側の誘導変数と最も内側の誘導変数を入れ替えることで、局所性を高めることができることを示しています。ただし、IF ステートメントによるループ内の制御フローにより、コンパイラーはこれを実行できません。プログラマーは、少し考えれば、このコードを図 3 のように書き直すことができます。
subroutine compute(a,b,c,d,n)
real*8 a(n,n)
real*8 b(n,n)
real*8 c(n,n)
real*8 d(n,n)
do k=1,n
do j=1,n
if (j.lt.k) d(k,j) = d(j,k)
enddo
enddo
do k=1,n
do j=1,n
do i=1,n
c(j,i) = c(j,i) + a(i,k) * b(k,j)
enddo
enddo
enddo
end subroutine 図 3: 入れ子のループが解消され最適化が容易に
このバージョンのコードを同じ方法でコンパイルすると、コンパイラーが 2 番目のループでループ交換の最適化を実行できるようになったこと分かります。
LOOP BEGIN at paper2a.f90 (12, 10)
remark #25444: Loop nest interchanged: ( 1 2 3 ) --> ( 3 2 1 )オプティマイザーは、メモリー参照のグループの空間的な局所性が低い場合 (つまり、後続の各参照が前の参照から遠く離れている場合) も指摘できます。メモリー参照が区別できないことが判明している場合や、ソースコードの注釈で修正できるファントムデータ依存関係が含まれている可能性がある場合にも通知できます。ループの入れ子がメモリーブロックで動作するように最適化されて局所性が向上すると、最適化レポートのリマークにブロック係数を最適に調整する方法が示されます。最後に、オプティマイザーがアンロールアンドジャム最適化の実行を選択すると、最適化を抑制するか、パフォーマンスを向上するためチューニングする方法の説明がレポートに出力されます。
最適なループの入れ子を記述するのは難しいため、このようなリマークを参考にして、コードのパフォーマンスを向上する変更の提案を適用すべきかどうかを検討してください。オプティマイザーは、このような変更を安全に行うのに十分な情報を持っていない可能性があります。
ベクトル化レポートの改善
OpenMP* 標準では、関数実装の前に #pragma omp declare simd を指定することで、ベクトル化された関数を作成できます。インテル® oneAPI コンパイラーの最適化レポートに関数のベクトル化を説明するセクションが含まれるようになりました。これは、ループのベクトル化で表示されるレポートによく似ていますが、LOOP ブロックの代わりに FUNCTION ブロックでラップされています。関数のベクトル化されたバージョンは複数作成することが可能で (例えば、256 ビット・ベクトルと 512 ビット・ベクトルを使用)、バージョンごとに個別のレポートセクションがあります。
ベクトライザーは、ベクトル化されたコード内のメモリー参照について、より多くの情報を提供するようになりました。最も詳細なレベルでは、ベクトル化された参照ごとにリマークが含まれ、参照がベクトル境界に揃えられているか、マスクされているかの説明と、参照のソース位置情報 (line:column) が提供されます。-g オプションを選択すると、ベクトライザーは、メモリー参照の限定された名前情報も含めます。
例:
LOOP BEGIN at test.c (2, 3)
remark #15389: vectorization support: unmasked unaligned unit stride load: A (4:12)
remark #15389: vectorization support: unmasked unaligned unit stride load: A (3:19)
remark #15388: vectorization support: unmasked aligned unit stride store: B (3:10)ここで、配列名 A と B は、コマンドラインで -g が選択されている場合にのみ表示されます。それ以外の場合、利用可能なデバッグ情報は配列名情報を生成するには不十分です。この情報を表示するには、必ずデバッグ用にコンパイルしてください。
ベクトライザーは、ギャザーロードの代わりにワイドロードとシャッフルを使用するように、近くのメモリー参照のグループを最適化することもできます (ストアについても同様です)。最適化レポートには、この VLS (ベクトルロード/ストア) 最適化に関するリマークが含まれるようになりました。次に例を示します。
LOOP BEGIN at test1.c (6, 3)
remark #15300: LOOP WAS VECTORIZED
remark #15305: vectorization support: vector length 4
remark #15597: -- VLS-optimized vector load replaces 3 independent loads of stride 3
remark #15598: load #1 from: arr1 [ test1.c (9, 11) ]
remark #15598: load #2 from: arr1 [ test1.c (7, 10) ]
remark #15598: load #3 from: arr1 [ test1.c (8, 11) ]
remark #15600: -- end VLS-optimized group
LOOP ENDその他いくつかのリマークが追加され、以前指摘されたレポート内のベクトル化されたループの順序に関する問題が修正されました。最後に、ベクトル化レポートのリマーク番号は、既存のリマーク番号に依存するツールの移行を容易にするため、一致する場合は常にインテル® コンパイラー・クラシックのリマーク番号と一致するように修正されました。
OpenMP* レポートの改善
オフロードターゲットが指定された場合、コンパイラーは 2 つの OpenMP* 最適化レポートを生成するようになりました。ホストの最適化レポートの名前はこれまでどおり myfile.optrpt です。デバイスの最適化レポートの名前は、選択されたターゲットから派生したものになります。例えば、-fopenmp-targets=spir64 が指定された場合、ターゲットレポートの名前は myfile-openmp-spir64.optrpt になります。さらに、ターゲットレポートには、レポートがオフロードされるデバイスコード用であることを強調するバナーが含まれます。
OpenMP* ディレクティブの NAMED 節は、最適化レポート内で可能な限り使用されるようになり、分かりやすくするためにソース名情報を提供します。これには、マップ名や共有プライベート化の使用が含まれます。OpenMP* ディレクティブで明示的に指定されるのではなく、コンパイラーによって暗黙的に生成された MAP 節は、そのように識別されます。
ホスト側とデバイス側の両方の最適化レポートに、いくつかの新しいリマークが追加されました。これらには、ループ構造で実行される変換に関するリマーク、デバイスで実行されるループに関するリマーク、スタックメモリーに割り当てられたカーネルローカル変数を識別するリマーク、およびループコラプスに関するリマークが含まれます。レポートは、インテル® コンパイラー・クラシックで生成されるレポートと同様に、分かりやすくするためにセクションに分割されています。
コード生成レポートの改善
最適化レポートのコード生成セクションは、以前のバージョンでは空でした。バージョン 2025.0 では、関数で使用されるレジスター、スタックに保存された呼び出し先保存レジスター、および関数スタックの使用に関するその他の情報を識別するレジスター割り当てレポートが含まれるようになりました。
今後の展望
インテル® oneAPI コンパイラーが生成する最適化レポートは、コードの最適化を理解し、パフォーマンスを向上するコードの書き直しのヒントを得ることを目的としています。バージョン 2025.0 では、これらのレポートをインテル® コンパイラー・クラシック標準に合わせ、期待以上の改善が行われました。これは現在進行中のプロジェクトです。今後のリリースでは、さらに多くの改善を予定しています。
最適化レポートを使用している方からのご意見をお待ちしています。さらなる改善のアイデアも大歓迎です! インテル® oneAPI DPC++/C++ コンパイラー (英語) およびインテル® Fortran コンパイラー (英語) のコミュニティー・フォーラムでフィードバックを送信して、ソフトウェア開発に役立つコンパイラー最適化ガイダンスをお知らせください。
コンパイラーのダウンロード
インテル® oneAPI DPC++/C++ コンパイラーとインテル® Fortran コンパイラーは、インテル® oneAPI 開発ツール製品ページからダウンロードできます。
このバージョンは、高度な基本ツール、ライブラリー、解析、デバッグ、コード移行ツールを含むインテル® ツールキットにも含まれています。
LLVM コンパイラー・プロジェクトへの貢献は、GitHub* (英語) を参照してください。
関連情報
- oneAPI 2025.0 リリース – AI とオープン・アクセラレーテッド・コンピューティングの開発者生産性を向上
- インテル® oneAPI DPC++/C++ コンパイラー・デベロッパー・ガイドおよびリファレンス (英語)
- インテル® Fortran コンパイラー・デベロッパー・ガイドおよびリファレンス (英語)
- ハードウェア・プロファイルに基づく最適化
- oneAPI GPU 最適化ガイド
- インテル® oneAPI DPC++/C++ コンパイラーでサニタイザーを使用してバグを素早く検出
- インテルの LLVM ベースのプロジェクト (英語)
サポート
我々にとって皆さんの成功は重要です。サポートが必要な場合は、次のリソースをご利用ください。
- インテル® Fortran コンパイラー・フォーラム (英語)
- インテル® oneAPI DPC++/C++ コンパイラー・フォーラム (英語)
- その他のサポートについては、oneAPI サポート (英語) を参照してください。
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
最新メジャーバージョン 2025 対応の日本語ドキュメント
エクセルソフトでは、バージョン 2025.0 に対応するドキュメントの日本語参考訳を一般公開しています。現在、以下のドキュメントに関する日本語参考訳をご参照いただけます。
- インテル® ソフトウェア開発ツールのリリースノート (ベース・ツールキット、ベース & HPC ツールキット)
- インテル® oneAPI DPC++/C++ コンパイラーのリリースノート
- インテル® Fortran コンパイラーのリリースノート
- インテル® VTune™ プロファイラーのリリースノート
- oneAPI for NVIDIA* GPU および AMD* GPU 導入ガイド