

この記事は、インテル社のウェブサイトで公開されている「Intel® oneAPI Toolkits 2025.2 – Parallelism Unleashed」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
2025年6月30日
Robert Mueller-Albrecht
ソフトウェア・プロダクト・マーケティング・マネージャー
インテル コーポレーション
インテル® oneAPI ベース・ツールキット、インテル® HPC ツールキット、インテル® AI ツール (英語) の前回のリリースから 3 カ月が経過し、それらのコンポーネントに多くの機能拡張が追加されました。今回の主な焦点は、HPC と AI における高度なマルチアーキテクチャー並列処理のための、より完全で使いやすい機能と相互運用性の包括的なセットを実現し、AI、グラフィックス、アクセラレーテッド・コンピューティング向けに最適化されたパフォーマンスと生産性を提供することでした。
新リリースの概要
この最新リリースの特筆すべきイノベーションの一部を次に紹介します。
- 次の C++26 標準に準拠するように拡張されたインテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語) の範囲ベース API を使用して、より効率的な並列アルゴリズム・プログラミング、コーディング・オプション、パフォーマンスを実現します。
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) の新しい SYCL DFT API を使用して、2D および 3D 非バッチ FFT に複数の GPU を組み合わせて使用できるようになりました。
- 高度なスレッド・フィルタリング、アクティブスレッドへの注力、エラー管理の簡素化により、ゲーム開発者や複雑なシミュレーション開発者の Visual Studio での生産性とデバッグ効率を向上します。さらに、最新のインテル® ディストリビューションの GDB (英語) の、さまざまなアセンブリー言語で記述された GPU カーネルにブレークポイントを設定できる機能は、多くの AI およびシミュレーション・ワークロードに含まれる、高度に並列化された行列乗算カーネルを GPU にオフロードするのに最適です。
- インテル® oneAPI DPC++/C++ コンパイラーの Vulkan および DirectX グラフィックス API との SYCL 相互運用性 (英語) が強化され、クロスプラットフォームの互換性、パフォーマンス、効率性が向上しました。レンダリングやデータ可視化などのアプリケーションに恩恵をもたらします。
インテル® HPC ツールキットは、インテル® データセンター GPU のデバイスコードでインテル® Fortran コンパイラーの強化された LLVM メモリー・サニタイザーをサポートしました。優れた生産性とパフォーマンス、堅牢なメモリーの使用が保証されます。
最新の C++ 26、OpenMP 6.0、Fortran 2023、MPI 4.1 機能の実装、階層型分散コンピューティングにおける並列処理での MPI、SYCL、OpenMP のシームレスな共存など、進化を続けています。
Fortran 2023 と OpenMP 6.0 について
- インテル® Fortran コンパイラーに、高度な論理型の処理を可能にして、Co-Array の割付け配列をサポートする Fortran 2023 Selected_Logical_KIND 組込み関数が追加されました。科学アプリケーションの並列コンピューティングと複雑なデータ構造の最適化に最適です。
- OpenMP 6.0 の新しい stripe ループ変換構造と、nowait 節のオプションのブール引数により、インテル® oneAPI DPC++/C++ コンパイラーとインテル® Fortran コンパイラーで非同期または同期オフロードを条件付きで選択可能になり、開発者はオフロード実行フローをさらに柔軟に制御できるようになりました。
主な機能改善の概要は、インテル® ソフトウェア開発ツール最新情報の以下のトピックで紹介されています。
⇒ インテル® ソフトウェア開発ツールのバージョン 2025.2 リリース: AI、グラフィックス、アクセラレーテッド・コンピューティング向けに最適化されたパフォーマンスと生産性
もちろん、開発ツールのすべてのコンポーネントは、最新および次世代のインテル® Xeon® プロセッサー、インテル® Core™ プロセッサー、インテル® Arc™ グラフィックスのカバレッジを引き続き拡大しています。これには、インテル® VTune™ プロファイラーのパフォーマンス分析機能への新しいシングルソケットのインテル® Xeon® 6 SoC (開発コード名 Granite Rapids-D) (コンパクトなフォームファクターのインテル® Xeon® プロセッサー・パッケージで、高帯域幅の産業用ゲートウェイや機内航空管制システムなどで広く使用されています) プラットフォーム認識の追加も含まれます。
スケーラブルな並列処理の相互運用性
インテル® コンパイラーに導入された機能には、SYCL と OpenMP の提案された拡張の初期実装が含まれます。
SYCL ジョイント行列拡張 API
試験的 SYCL 名前空間 sycl::ext::oneAPI::experimental::matrix は、ジョイント行列演算で使用される新しいデータ型を定義します。
using namespace sycl::ext::intel::experimental::matrix;
template <typename Group, typename T, use Use, size_t Rows,
size_t Cols, layout Layout = layout::dynamic>
struct joint_matrix;
enum class use { a, b, accumulator};
enum class layout {row_major, col_major, dynamic};一般的なメモリーロード、ストア、ポインター演算は、SYCL ワークグループ全体に適用でき、データをプリフェッチして効率的に実行できます。ポインターはオーバーロード可能です。
void joint_matrix_mad(Group g, joint_matrix<>&D,
joint_matrix<>&A, joint_matrix<>&B, joint_matrix<>&C);
void joint_matrix_apply(Group g, joint_matrix<>&jm, F&& func);
void joint_matrix_apply(Group g,
joint_matrix<>& jm0, joint_matrix<>& jm1, F&& func);
void joint_matrix_copy(Group g, joint_matrix<Group, T1, Use1,
Rows, Cols, Layout1> &dest,
joint_matrix<Group, T2, Use2, Rows, Cols, Layout2> &src);行列の乗算と加算 (D=A*B+C) は、要素ごとの演算、活性化関数、(逆) 量子化、データ型変換を含む行列のコピーなど、基本的な操作をすべてサポートしています。
void joint_matrix_fill(Group g, joint_matrix<>&dst, T v);
void joint_matrix_load(Group g, joint_matrix<>&dst,
multi_ptr<> src, size_t stride, Layout layout);
void joint_matrix_load(Group g, joint_matrix<>&dst,
multi_ptr<> src, size_t stride);
void joint_matrix_store(Group g, joint_matrix<>src,
multi_ptr<> dst, unsigned stride, Layout layout);
void joint_matrix_prefetch(Group g, T* ptr, size_t
stride, layout Layout, Properties properties);SYCL 行列とテンソルを使用することで計算オブジェクトのプロパティーを効率的に表現して操作できるようになり、シミュレーション、高度な数値微分方程式、ビジュアル・コンピューティング、CGI VFX、金融リスク分析、ゲーム、AI などの広範な計算を高速化するビジョンと正味の効果が得られます。これらの計算はすべて、SPIR-V 協調行列拡張と互換性のある行列およびテンソル演算用の統合インターフェイスにより行われます。
このアーキテクチャーにより、統合ジョイント行列が本質的にスケーラブルになり、異なるプラットフォームやアーキテクチャー間で移植できます。
統合ジョイント行列の SYCL 拡張の詳細については、次の記事を参照してください。
⇒ 統合ジョイント行列の SYCL 拡張
OpenMP コンポーザビリティーの強化
OpenMP は、移植性とスケーラビリティーに優れたモデルを提供するように設計されていて、ラップトップからスーパーコンピューターまで、さまざまなプラットフォーム用の並列アプリケーションを開発するための柔軟なインターフェイスをプログラマーに提供します。
主な機能は、以下のとおりです。
- ディレクティブベースの並列処理。C や Fortran 開発者には非常に自然に感じられるものです。
- 共有メモリーモデル。共有メモリードメインの唯一の制限は、オペレーティング・システムのサポート状況です。
- タスクとループの並列処理。既存のコードに並列処理を簡単に追加できます。
- デバイスオフロード。高速化とカスタムルーチン実行を実現します。
- アーキテクチャーとコンパイラー間の移植性。OpenMP のオープン・スタンダード・アプローチにより実現します。
複数のソケット、複数のオフロード・ソフトウェア・プログラミング・モデル、そして異なる NUMA ドメインからなる環境を考えてみましょう。FPGA、カスタム・アクセラレーター、チップレット、GPU の人気が高まり、競争が激化するにつれて、メモリー・アーキテクチャーはさらに複雑になっています。
我々のコンポーザビリティー・アプローチは、最小限の変更で SYCL ライブラリー、OpenMP、MPI の共存を可能にします。もちろん、ほかの多層型のハイパフォーマンス・コンピューティング・スタックと同様に、複雑になるとパフォーマンス・チューニングの要件も増えます。しかし、図 1 に示すように、その概念は非常に単純です。
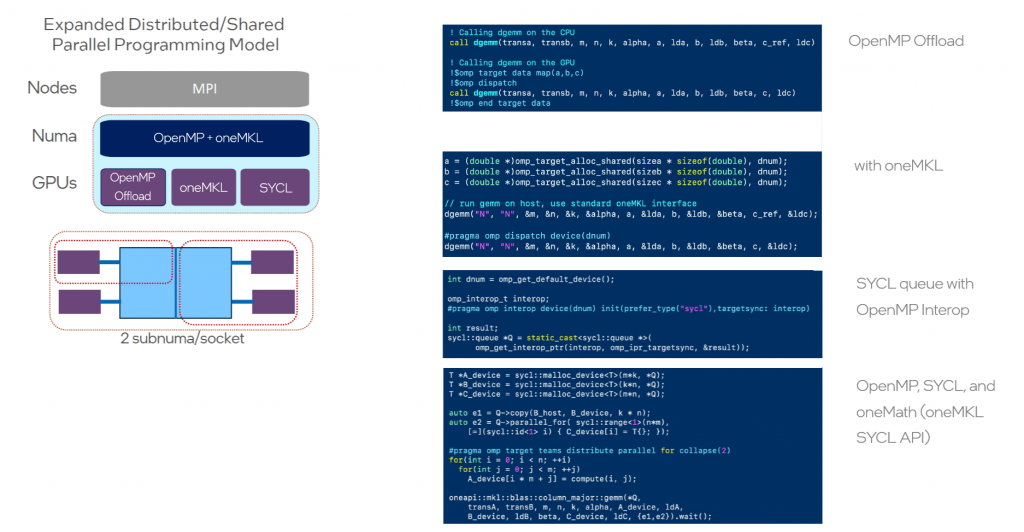
図 1: OpenMP コンポーザビリティーのスケーリング
OpenMP コンポーザビリティーの詳細については、次の記事を参照してください。
⇒ OpenMP と科学計算の将来
SYCL の仮想関数
仮想関数は、言語の誕生以来、現代の C++ ソフトウェア開発における不可欠な要素となっています。ハイパフォーマンス科学計算で広く使用されている Kokkos C++ パフォーマンス移植性インターフェイス (英語) などの一般的なバックエンド抽象化は、仮想関数に依存しています。
ただし、SYCL 仕様の 1 定義ルール (ODR) による仮想継承の使用には若干の制限があります。仮想メンバー関数はデバイス関数内で呼び出せないため、一部のコードベースを SYCL に移植する際に複雑な問題が発生します。
この問題に対処するため、我々は oneAPI カーネル・プロパティー拡張機能 (indirectly_callable プロパティー) を導入して、仮想関数をすべての制限を含む特別なデバイス関数として宣言しています。

図 2: oneAPI カーネル・プロパティー拡張機能を利用した基本的な仮想クラス継承のセットアップ
SYCL での仮想関数の使用の詳細については、次の記事およびプレゼンテーションの録画 (英語) を参照してください。
⇒ SYCL 拡張の重要な部分: C++ 仮想関数と SPIR-V バックエンド (英語)
インテルが表明したオープンソース・コミュニティーに対するサポートに沿って、コンパイラー開発者は、OpenMP、SYCL、MPI などの並列プログラミング手法、SPIR-V などのバックエンド定義、LLVM などのコンパイラー・フレームワーク、TensorFlow や PyTorch などの AI フレームワークなど、これらの議論やその他の最先端のソフトウェア開発フレームワークに関する議論に積極的に貢献しています。
高速画像処理と視覚化
画像処理とビジュアル・コンピューティングは、多くのアクセラレーテッド・コンピューティング、ゲーム、CGI VFX ワークロードの重要な要素です。
そのため、インテル® oneAPI DPC++/C++ コンパイラーの Vulkan および DirectX グラフィックス API との SYCL 相互運用性が強化され、クロスプラットフォームの互換性、パフォーマンス、効率性が向上しました。これらの強化がインテル® DPC++ 互換性ツールで完全に認識されるようになったことで、CUDA GPU オフロードコードをオープン標準のクロスアーキテクチャーおよびマルチアーキテクチャー SYCL コードに移行するプロセスにも反映されるようになりました。インテル® DPC++ 互換性ツールで、一般的な AI およびアクセラレーテッド・コンピューティング・アプリケーションで使用される 357 の API を自動的に移行できるようになりました。
バインドレス・イメージは、SYCL 2020 標準の画像サポートが拡張され、デバイスへの画像の保存方法と、使用するメモリー・アクセス・モデル (統合共有メモリー (USM)、バッファーアクセサー、デバイス最適化メモリーレイアウト、インポートメモリーなど) を制御できるようになります。アクセサーベースのメモリー・アクセス・リクエストを超えて、ランタイム・イメージ・レンダリング、ミップマップ、キューブマップ、イメージ配列などをサポートします。
柔軟な補助コピー機能により画像データをコピーして再解釈し、全体像を完成できます。
これにより、CPU ホストプロセスとアクセラレーター・デバイス間で転送されるデータの量を最小限に抑えることができます。
実行フローは図 3 から、よりシンプルでリソース効率が大幅に向上した図 4 に代わります。
図 3: 相互運用性のないホストとデバイス間のデータ転送
図 4: 相互運用性のあるホストとデバイス間のデータ転送
SYCL 画像処理フレームワークに外部メモリーをインポートするための API を導入することにより、SYCL と Vulkan または DirectX 12 のコンテキスト内で同じメモリー割り当てを再利用して、余分なコピーステップを 2 つ減らしました。
SYCL と DirectX および Vukan の相互運用性の詳細については、次の記事を参照してください。
⇒ バインドレス・イメージ・メモリーの SYCL と DirectX および Vulkan の相互運用性 (英語)
ライブラリー並列処理によるパフォーマンス
スケーラブルなマルチアーキテクチャー並列処理とは、一般的な言語や言語拡張で高度な並列プログラミングの概念をサポートすることだけではありません。言語拡張と基盤となるハードウェア機能の両方から直接メリットを受けることができる、最適化されたパフォーマンス・ライブラリーの豊富なエコシステムも重要です。
インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) は、インテル® IPP のワープ・パースペクティブ関数と最近傍補間または OpenCV を使用して、32 ビット浮動小数点画像の操作とアライメントを高速化することにより、インテル® AVX-512 に対応したインテル® CPU での高精度画像処理を高速化します。
画像処理に加えて、信号処理でも、インテル® AVX2 およびインテル® AVX-512 に対応した CPU での 16 ビット・データのパフォーマンスが大幅に向上します。
インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) は、高速フーリエ変換 (FFT) のクロスアーキテクチャー並列実行を新たなレベルに引き上げ、新しい SYCL DFT API を使用することで、複数の GPU を組み合わせた 2D および 3D 非バッチ FFT 処理を容易に実現します。
分散マルチノード・クラスターで CPU に複数の GPU を接続するのは、HPC における一般的なプラットフォーム構成です (前述の SYCL および MPI との OpenMP コンポーザビリティーを参照)。
OpenMP 6.0 の新しい stripe ループ変換構造と、nowait 節のオプションのブール引数により、インテル® コンパイラーで非同期または同期オフロードを条件付きで選択可能になり、オフロード処理を柔軟に制御できるようになりました。
インテル® MPI ライブラリーで以下の機能を利用できるようになりました。
- I_MPI_OFI_PROVIDER リストを設定する新機能により、プロバイダー初期化の制御が強化されました。
- 完全な MPI 4.1 機能に加え、継続的なアップデートにより、将来の安定性、移植性、および MPI 4.1 へのアップデートとの互換性を確保します。
- 新たに拡張されたマルチスレッド機能により、集合操作全体にわたってリソース利用率とパフォーマンスが向上し、デバイス主導型 RMA の相互運用性とパフォーマンスが向上します。
これらにより、CPU のみを使用するラップトップから、HPC および AI 向けのエクサスケール・スーパーコンピューターに至るまで、スケーラブルな並列処理が実現します。
CPU と GPU における AI のスーパーチャージ
AI に関しては、PyTorch およびインテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) に対するインテルの貢献としてさらなる最適化を追加しました。
インテル® Core™ Ultra プロセッサー (シリーズ 2)、P-cores 搭載インテル® Xeon® 6 プロセッサー、インテル® Arc™ GPU 向けのインテル® oneDNN の最新の最適化は PyTorch 2.7 リリースにアップストリームされ、BERT、Llama、GPT などの一般的な AI 推論ワークフローもインテル® Xeon® 6 プロセッサーでスーパーチャージされます。
インテル® VTune™ プロファイラーの新しい分析ツールの機能を活用してインテルのクライアント GPU と NPU の AI パフォーマンスを効率化および最適化して、DirectML ベースの AI アプリケーションのパフォーマンスを向上できます。
PyTorch ベースの AI アプリケーションの高速化に対するインテルの支援の詳細については、次のブログを参照してください。
⇒ インテル® GPU 上で PyTorch 2.7 を高速化 (英語)
次のビデオも参照してください。
⇒ AOTInductor を使用してインテル® GPU にコンパイル済み PyTorch モデルをデプロイ (英語)
⇒ インテル® GPU を使用した PyTorch エクスポートの量子化 (英語)
並列コードを制御する
AI PC で実行する場合でも、スーパーコンピューターで実行する場合でも、包括的で高度に統合された並列処理により、あらゆるワークロードの実行をスケーリング、最適化、効率化できます。MPI、OpenMP、SYCL、PyTorch、Vulkan、DirectX などのシームレスな相互運用性により、AI、HPC、画像処理のための開発ソリューションを提供します。
最新の開発ツール、バージョン 2025.2 を今すぐダウンロードしてください。
関連情報
ニュース・アップデート
アクセラレーテッド・コンピューティング
- OpenMP と科学計算の将来
- 光と物質の相互作用動力学の理解を深める (英語) (HPC におけるインテル® oneMKL と混合精度)
- 統合ジョイント行列の SYCL 拡張
- SYCL 拡張の重要な部分: C++ 仮想関数と SPIR-V バックエンド (英語)
- バインドレス・イメージ・メモリーの SYCL と DirectX および Vulkan の相互運用性 (英語)
AI とマシンラーニング
- インテル® GPU 上で PyTorch 2.7 を高速化 (英語)
- AOTInductor を使用してインテル® GPU にコンパイル済み PyTorch モデルをデプロイ (英語)
- インテル® GPU を使用した PyTorch エクスポートの量子化 (英語)
製品および性能に関する情報
性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
インテル® ソフトウェア開発ツール向けサポートサービス
エクセルソフトが提供するインテル® ソフトウェア開発ツール向けサポートサービスでは、インテル® ソフトウェア開発ツールの旧バージョンから新バージョンへの移行、CUDA から SYCL へのコード移行、他社製 GPU とのコード互換など、新しい環境でこれまで通り業務を遂行するための移行を支援します。製品の移行に関してお悩み、質問などお気軽にお問い合わせください。