概要
ビッグデータの解析とマシンラーニングのパフォーマンスを大幅に向上

ビッグデータは、さまざまな業界や分野で生成される増加するデータ、多様性およびその速度性から価値を見出すことにより、コンピューティングの世界を変えようとしています。ゲノム科学、リスク、ソーシャル・ネットワークと消費者の傾向の分析などは、現代のコンピューティングにおける大規模データセットのハイパフォーマンス解析のほんの一例です。
これらのタスクにおいて、計算速度は重要な要素と言えます。インテル® Data データ・アナリティクス・ライブラリー (インテル® oneDAL) は、ソフトウェア開発者が短い開発期間でアプリケーションのパフォーマンスを向上させ、市場へ出すことを支援するように設計されています。利用可能な計算リソースを使って大規模データセットをより高速に解析できます。
次世代プロセッサーのパフォーマンスを活用できるよう、プロセッサーが利用可能となる前に、インテル® oneDAL もアップデートされます。新しいプロセッサーが出荷された時点で、最新バージョンのインテル® oneDAL とリンクするだけで、コードは最新プロセッサーのパフォーマンスを最大限に活用できるようになります。
詳細・新機能 技術情報 iSUS 関連記事製品種類
スイート製品に同梱
インテル® oneDAL は単体で販売されておりません。以下製品に同梱されます。

インテル® oneAPI ベース・ツールキット
1 つのプログラミング・モデルで複数のアーキテクチャー (CPU、GPU、FPGA) にわたって高いパフォーマンスを発揮できるコードの開発を支援します。
インテル® oneAPI ベース & HPC ツールキット
DPC++/C++、Fortran コンパイラーと MPI 開発ツールにより、CPU およびアクセラレーターまたはそれらのクラスターへ最適化された HPC アプリケーションの開発を支援します。
インテル® oneDAL 2025
バージョン 2025.1 新機能およびシステム要件
新機能やシステム要件などの詳細は、以下のリリースノートや動作環境、およびインテル社公開の情報を参照ください。
最新バージョンに関する日本語情報をお探しの方は、ライブラリーが同梱されているツールキットのリリースノートをご参照ください。
インテル® oneDAL に関するその他のドキュメントについては、こちらを参照ください。
詳細
インテル® パフォーマンス・ライブラリーによるマシンラーニングの高速化
インテル® oneDAL は、高度な数値演算ライブラリーであるインテル® oneMKL と同じチームによって開発されています。このチームは、インテル® アーキテクチャー・ベースのシステムから最大限のパフォーマンスを引き出すため、インテル® プロセッサーの設計チームと協力しつつ作業を行っています。
基本的なデータ分析からマシンラーニングまで、開発で必要とするアルゴリズムにこれらの最適化されたビルディングブロックを役立てることができます。
インテル® oneDAL はビックデータのエコシステムに最適

インテル® oneDAL は、データ解析パイプラインの次のすべてのステージに注目します。
- 前処理
- 変換
- 解析
- モデル化
- 検証
- 意思決定
ハードウェア向けに最適化
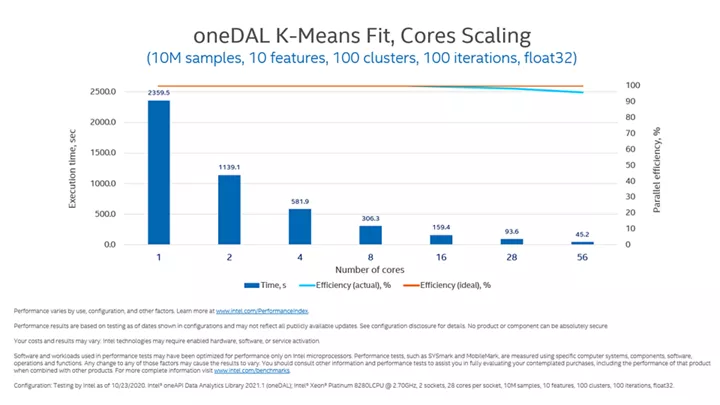
インテル® oneDAL の各関数は、計算速度を向上させるために、それぞれのプロセッサーの命令セット、レジスター、およびメモリー・アーキテクチャー向けに高度に最適化されています。
インテル® oneDAL は、IoT ゲートウェイからバックエンド・サーバーをターゲットとするインテル® Atom® プロセッサー、インテル® Core™ プロセッサーおよびインテル® Xeon® プロセッサー を含む、さまざまなインテル® プロセッサーをサポートし、IoT ゲートウェイとバックエンド・サーバーなどの複数プラットフォーム間で処理されるそれぞれの解析から、アプリケーション・パフォーマンスの向上を支援します。
開発作業の生産性向上
簡単に利用でき、すべての処理段階で事前に最適化が可能な、ソフトウェア開発の時間を短縮する高度な C++ と Java* 、Python* データ解析関数を利用することができます。
- 一般的によく利用されるアナリティクス・プラットフォーム (Hadoop*、Spark*) とデータソース (SQL、Non-SQL、ファイル、インメモリー) に簡単に接続でき、高いスループットを実現
- サポートされるすべてのバッチ、ストリーミングおよび分散コンピューティング・モデルは、アプリケーションのデータ・セット・サイズとパフォーマンス要件をカバー。
アルゴリズム (データ解析: 特性評価、集計、変換)
| アルゴリズム | 説明 |
|---|---|
| 低次モーメント | データセットの基本特性 (合計、平均、2 次モーメント、差異、標準偏差など) を計算します。 |
| クォンタイル | クォンタイルの位数で等分されたデータ分布を集計するクォンタイルを計算します。 |
| 相関行列と分散共分散行列 | 特徴ベクトルのペアの統計的関係を定量化します。 |
| コサイン距離行列 | コサイン距離を使用して、特徴ベクトルのペアの類似性を評価します。 |
| 相関距離行列 | 相関距離を使用して、特徴ベクトルのペアの類似性を評価します。 |
| コレスキー分解 | 対称正定値行列を下位三角行列とその転置の積に分解します。線形システム、非線形最適化、カルマンフィルターなどを解くための基本操作として使用されます。 |
| QR 分解 | 一般行列を直交行列と上三角行列の積に分解します。線形逆問題と最小二乗問題を解くのに使用されます。また、固有値と固有ベクトルの計算にも使用されます。 |
| 特異値分解 (SVD) | 行列を左特異ベクトル、特異値、右特異ベクトルの積に分解します。主成分分析、線形逆問題の計算、データ・フィッティングに使用されます。 |
| 主成分分析 (PCA) | 入力特異ベクトルを互いに直交する主成分の新しいセットに変換することでデータの次元を減らします。 |
| K 平均法 | データセットをほぼ同じデータポイント数のクラスターに分割します。各クラスターは、そのクラスターのすべてのデータポイントの平均であるセントロイド (中心) により表されます。 |
| 期待値最大化 | モデルのパラメーターの最大尤度を推定します。クラスタリング手法としてガウス混合モデルで使用されます。非線形次元縮退、欠測値問題にも使用できます。 |
| 外れ値検出 | 異常に離れた観測点とほかの観測点を識別します。特徴ベクトル全体 (多変量) または 1 つの特徴値 (単変量) を考慮して、外れ値かどうか決定できます。 |
| 相関ルール | 特定の信頼レベルで変数の関係を検出します。 |
| 線形および放射基底関数カーネル | データをより高い次元の空間にマップします。 |
| 品質メトリック | 数値のセットを計算し、解析アルゴリズムによって返される結果の定量的特性を評価します。メトリックには、混同行列、正解率、適合率、再現率、F 値などが含まれます。 |
アルゴリズム (マシンラーニング: 回帰、分類、その他)
| アルゴリズム | 説明 |
|---|---|
| ディープラーニングのためのニューラルネットワーク | コンピュータが観測データから学習することを可能にするプログラミングの典型です。 |
| 線形回帰 | 線形方程式を観測データに当てはめることで、従属変数と 1 つ以上の説明変数の関係をモデル化します。 |
| ナイーブベイズ分類器 | ラベルを割り当てることで、観測値を別々のクラスに分割します。ナイーブベイズは、特徴間の独立性を仮定する確率的分類器です。テキスト分類と医療診断によく使用され、特徴間にある程度の従属関係がある場合でもうまく動作します。 |
| ブースティング | 弱分類器の正解率に応じて繰り返し重み付けを見直し、一連の重み付けされた弱分類器をまとめて強分類器を作成します。弱分類器が決定木となります。AdaBoost (二項分類器)、BrownBoost (二項分類器)、LogitBoost (多クラス分類器) を含むブースティング・アルゴリズムを利用できます。 |
| SVM | SVM (Support Vector Machine) はポピュラーな二項分類器です。観測された特徴ベクトルを 2 つのクラスに分割する超平面を計算します。 |
| 多クラス分類器 | SVM などの二項分類器を使用して多クラス分類器を作成します。 |
| ALS | ALS (Alternating Linear Square) は、多くのユーザーから収集した嗜好情報に基づいて、ユーザーの嗜好予測を行うための協調フィルタリングの方法です。 |
| 決定木 | データマイニングで一般的に使用される方法です。目的は、 決定木を 予測モデルとして使用して、項目 (分岐で表される) に関する観察から、項目の目標値に関する結論に至るまでの複数の入力変数に基づいて、ターゲット変数の値を予測するモデルを作成することです (葉で表される)。 |
| ランダムフォレスト |
学習時に多数の 意思決定木を構築し、クラスの分類の モードや個々の木の平均予測 (回帰) を出力することで動作する 分類、 回帰などの アンサンブル学習法です。 |
| k近傍法(K-Nearest Neighbor algorithm: KNN) | 関数が局所的にしか近似せず、すべての計算が分類まで延期されるタイプの インスタンス・ベース・ラーニングまたは 遅延ラーニングです。 |
ドキュメント
オンライン・コンテンツ
関連ページ


関連製品

お知らせ
2024年11月6日、インテル社よりリリースが発表されたインテル® ソフトウェア開発ツールの最新バージョン 2025 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2025 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
2023年11月24日、インテル® oneDAL 2024 が同梱されるインテル® ソフトウェア開発ツールに対応する有償サポートサービスの提供を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2024 を無料でダウンロードしてご利用いただけます。
2022年12月19日、インテル® oneDAL 2023 が同梱されるインテル® oneAPI 2023 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2023 を無料でダウンロードしてご利用いただけます。
2021年 12月 23日、インテル® oneDAL 2022 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2022 を無料でダウンロードしてご利用いただけます。
2019年 12月 9日、インテル® oneDAL 2021 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2021 を無料でダウンロードしてご利用いただけます。
2019年 12月 18日、インテル® oneDAL 2020 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2020 を無料でダウンロードしてご利用いただけます。
2018年 9月 13日、インテル® oneDAL 2019 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2019 を無料でダウンロードしてご利用いただけます。
FAQ
インテル® oneDAL は、データを情報に変換する最適化された関数を提供することにより、ビッグデータの解析やマシンラーニングのパフォーマンスを向上する Python*、C++、Java* ライブラリーです。既存の開発環境に簡単に追加できます。
必要なインテル® oneDAL のコピー数は、インテル® oneDAL API を使用してコードの記述、コンパイル、テストを行っている開発者の数と、コンパイルおよびリンクを行うビルドマシン (フルセットのインテル® oneDAL 開発ツールが必要です) の数によって決まります。詳細は、 EULA を参照してください。
はい。インテル® oneDAL を購入すると、インテル® oneDAL の一部のファイルをアプリケーションとともに再配布する権利が得られます。インテル® oneDAL の評価版には、この権利は含まれません。再配布できるファイルは、製品ライセンス付きのインテル® oneDAL ディストリビューションに含まれている redist.txt にリストされています。
いいえ。コピーごとにロイヤルティーを支払う必要はありません。詳細は、インテル® oneDAL エンド・ユーザー・ソフトウェア使用許諾契約書 ( EULA) を参照してください。
一般に、リンク可能なファイル (Windows® では .DLL および .LIB ファイル、Linux* では .SO および .A ファイル) を再配布できます。インテル® oneDAL を購入 (またはサポートサービスを購入して更新) すると、再配布可能なファイルのリストを含む redist.txt ファイルが提供されます。インテル® oneDAL の評価版には、この権利は含まれません。詳細は、 EULA を参照してください。
インテル® oneDAL は Python*、C++、Java* API を提供します。
いいえ。インテル® コンパイラーを含む、任意のコンパイラーを使用して、アプリケーションのビルドおよびライブラリーのリンクを行うことができます。
- インテル® MKL は、処理するデータ全体がメモリーに収まる場合に有用です。インテル® oneDAL は、データが一度にメモリーに収まりきらない状況でも処理できます。インテル® oneDAL は、アプリケーションがデータの一部分をチャンクとして処理し、最後に最終結果を取得することを可能にします。
- インテル® MKL は、Fortran と C API をサポートします。インテル® oneDAL は、C++ と Java* API をサポートします。
- インテル® MKL を使用する場合、アプリケーションはデータの管理 (データソースに接続し読み取る) にほかのツールやライブラリーを必要とします。インテル® oneDAL は、データ管理機能を持っています。アプリケーションは、各種ソース (ファイル、インメモリー・バッファー、SQL データベース、HDFS など) に直接アクセスできます。
- いくつかのアルゴリズム (行列分解、低次モーメント、分位など) は、インテル® MKL にもあります。
インテル® レジストレーション・センターで操作します。
操作手順やよくあるご質問、トラブルシューティングは、インテル
® レジストレーション・センター操作マニュアルを参照ください。
最新版、または旧バージョンのダウンロードは、インテル® レジストレーション・センターで行います。
詳細は以下ページを参照ください。