ゴール
PDF Xpress .NET SDK を利用して、C# でコマンド ライン プログラムを作成します。 これは、PDF ドキュメントをページ単位に一連の画像に変換することができます。 このプログラムでは、変換する開始ページと終了ページ、および保存するビットマップ ファイル形式 (JPEG、BMP、GIF、および PNG) をユーザーが選択できるようになります。
要件
C# 開発環境 (この例では Visual Studio を使用しています)
PDF Xpress の無償評価版は、こちら。
Accusoft の PDF Xpress は、PDF ファイルを編集、注釈、情報の付加、あるいは情報を抽出するための素晴らしいツールです。 しかし、Web ページのホスティングのために PDF ページを画像に変換することが必要になることがあります。 PDF ファイル全体を取得する代わりに、素早く、その 1 ページだけを必要とする人々のためのギャラリーを作成することが求められます。
PDF Xpress で、それが可能になります。 このサンプル プログラムでは、C# でコマンドライン ツールを作成し、PDF Xpress を使用するための基本的なコマンドを示します。 これにより、ユーザーは PDF 文書を一連の画像ファイルに変換し、ページごとに 1つのファイルをユーザーが指定したビットマップ画像 (BMP、JPEG、GIF、PNG) として作成することができます。 一般的なプログラムの実行は次のようになります。
[csharp]PDFXpressConvertPDF2Image [PDF ファイル] <img src=""> [開始ページ番号] [終了ページ番号][/csharp]
“画像フォーマット”、 “開始ページ番号”、 “終了ページ番号”はすべてオプションであり、デフォルトでは PDF ファイルの各ページの JPEG 画像が作成されます。
前提条件
Accusoft PDF Xpress .NET SDK (評価版) をインストールする必要があります。 CMapフォルダと Font フォルダを、PDF Xpress がインストールされている Support フォルダから ‘library’ というフォルダにコピーします。 セットアップは次のようになります。
[csharp]PDFXpressConvertPDF2Image
├──library
│ ├───CMap
│ └───Font[/csharp]
PDF ファイルは、実行可能ファイルと同じフォルダに置きます。 すぐに実行したい場合は、サンプル コードをダウンロードしてください。
詳細な説明は、コードウォークスルーに従ってください。
セットアップを開始する
プログラムを作成するために、Visual Studio 2017 Community Edition と PDF Xpress .NET SDK キットを使用します。 以前のバージョンの Visual Studio も PDF Xpress と互換性があります。
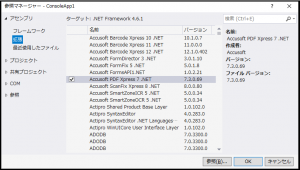
PDF Xpress をダウンロードしたら、プロジェクトを C# コンソール アプリケーションとして作成します。 正しい名前空間を活用するには、参照を編集する必要があります ([ソリューション エクスプローラー] で [参照] を右クリックするか、[プロジェクト | 参照の追加] をクリックしてください)。
[拡張] を選択し、 “System.Drawing” と “Accusoft PDFXpress7.NET” がチェックされていることを確認してください:
PDF to Image コード ウォークスルー
まず、コードが正しく動作するためには、次の名前空間が必要です。
[csharp]using Accusoft.PdfXpressSdk;
using System.IO;
using System.Drawing;[/csharp]
この場合、メソッドを保持するためにクラス “PDFXpressConverter” が使用されます。 正しく設定されていることを確認するために、コンストラクターに初期化設定をロードすることができます:
[csharp]public PDFXpressConverter()
{
pdfXpress = new Accusoft.PdfXpressSdk.PdfXpress();
string resourcePath = Environment.CurrentDirectory + @"\library\";
string fontPath = resourcePath + "Font";
string cmapPath = resourcePath + "Cmap";
//init the PDFXPress object
pdfXpress.Initialize(fontPath, cmapPath);
}[/csharp]
これは PDF Xpress オブジェクトに、フォントと文字のマッピング ファイルが “library” フォルダにあることを伝えます (Font と CMap のコピーを実行可能ファイルとともに “library” というフォルダに保存してください)。
プログラムがきれいに終了するように、deconstructor をセットアップしてメモリから PDF Xpress オブジェクトをクリアします:
[csharp]~PDFXpressConverter()
{
//PDF オブジェクトを適切に破棄します
if (pdfXpress != null)
{
pdfXpress.Dispose();
pdfXpress = null;
}
}[/csharp]
主な機能の説明は省略します。ファイル名、ファイル形式、開始ページ、終了ページの設定をロードして、PDF を画像に変換します。 変換メソッド ConvertPDF2Image を直接見てみましょう:
[csharp]public int ConvertPDF2Image(string PDFFileName, String format = "jpg", System.Int32
pageStart = 0, System.Int32 pageEnd = -1)[/csharp]
最初に行うことは、PDF ファイルを PDF Xpress オブジェクトに読み込むことです。
[csharp]System.Int32 index = pdfXpress.Documents.Add(PDFFileName);[/csharp]
ファイルを PDF Xpress オブジェクトに整数として追加した結果をなぜ保存するのか、疑問に思うかもしれません。 この場合、”index” はオブジェクト内のドキュメントコレクションを追跡します。 つまり、複数の PDF を 1 つの PDF Xpress オブジェクトに格納し、それぞれ異なる番号で追跡できます。
次にレンダリング オプションを設定します。 これを 300 x 300 の解像度で保存します。 ここではちょっとしたヒントがあります。 レンダリング オプションの 1 つでは、アノテーションもキャプチャできます。 PDF Xpress API ドキュメントの詳細を参照してください。
[csharp]RenderOptions renderOpts = new RenderOptions();
renderOpts.ProduceDibSection = false;
renderOpts.ResolutionX = 300;
renderOpts.ResolutionY = 300;[/csharp]
エラー訂正を行うメンバー関数の 1 つを見てみましょう。 “pageEnd” が “-1” に設定されていると、すべてのページを処理します。 PDF Xpress は、一度ファイルを読み込むと、総ページ数を表示するための単純なプロパティを持っています:
[csharp]//if they give us -1 as the parameter, do all the pages
if (pageEnd == -1)
{
pageEnd = pdfXpress.Documents[index].PageCount – 1;
}[/csharp]
pageEnd を最後のページから 1 を引いた値に設定するのはなぜですか? ページは 0 が最初のページであるので、500 ページのドキュメントであれば、最後のページは “499” になります。
最後に、PDF 文書を受け取り、ページ範囲の各ページを画像として保存するメソッドの部分を次に示します。
[csharp]//Start from the first page to be converted, and keep going through
for (int pageIndex = 0; pageStart <= pageEnd; pageStart++)
{
//Render the current PageStart page using the options above to the Bitmap object
using (Bitmap bp = pdfXpress.Documents[index].RenderPageToBitmap(pageStart, renderOpts))
{
//save the bitmap object as a file
bp.Save(outputFileBase + pageStart.ToString(numberFormat) + "." + format, imageType);
}
//show current progress
Progress(++pageIndex, totalPages);
//ending the progress line
}
System.Console.WriteLine();[/csharp]
クイックノート: “Progress(++pageIndex, totalPages);” は、レンダリングされている現在のページと、残されているページの数を表示する単純なメソッドです。
[csharp]using (Bitmap bp = pdfXpress.Documents[index].RenderPageToBitmap(pageStart, renderOpts))[/csharp]
PDF Xpress SDK の使い方はとても簡単です。 1 行のコードは、すべてのテキスト、フォント、イメージを含む PDF ページ全体を受け取り、それをビットマップ オブジェクトにカプセル化します。
興味が湧いてきましたか? サンプル コードをダウンロードして今すぐ試してみてください!
Accusoft PDF Xpress 製品ページ:


