データ センターを円滑に運用するためには、サーバー ハードウェアのエラーやトラブルを回避することが第一です。仮想化時代においては、サーバー ハードウェアのメーカーを問わず、ハイパーバイザーに目を配り、不具合や故障につながる前に初期の問題を解消することが重要です。
ハードウェアは、IT インフラの最初の層であり、これが故障すると、サーバー、オペレーティング システム、アプリケーション、プロセスなど、他のすべてが故障します。ハードウェアは様々な場所で故障する可能性があるため、自動的に監視することが非常に重要です。
PRTG は、Dell、HPE、IBM などの有名メーカーのすべてのハードウェアをスキャンして監視します。様々な通知オプションにより、問題を見逃すことなく、緊急時にも迅速に対応することができます。PRTG には、システムの健全性や個々のコンポーネントの監視を含む、ベンダー固有のハードウェア センサーが多数搭載されています。ここでは、Dell、HPE、IBM のハードウェアを監視する PRTG のトップ センサーをご紹介します。
Ping センサー
ハードウェアの監視は、簡単な ping テストから始まります。これは、すべてのサーバーが到達可能かどうかを確認する簡単な方法です。Ping テストが失敗した場合、サーバーの電源が切れていたり、スイッチに問題があったり、ケーブルの抜き差しや破損が原因でエラーが発生している可能性があります。PRTG には、この目的のために Ping センサーと Cloud Ping v2 センサーが用意されています。
System Uptime センサー
サーバーのアクセス性に加えて、アップタイムが決定的な意味を持ちます。ネットワークでは、アップタイムはサーバーの可用性と信頼性によって定義されます。また、アップタイムは、ほとんどの場合、SLA の重要な指標です。SNMP System Uptime センサーを使用することで、サーバーの現在、最小、最大の稼働時間を常に把握することができます。
さらに、このセンサーをレポートに組み込んで、サーバーの可用性を文書化することをお勧めします。
CPU センサー
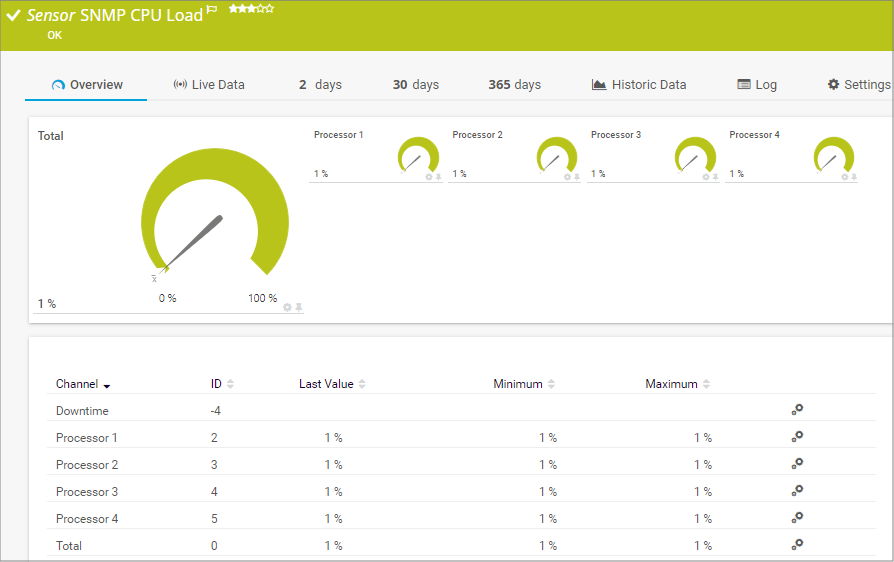
すべてのサーバーの心臓部は CPU です。サービスやプロセスなどによって引き起こされる高負荷は、通常、顕著な悪影響を及ぼします。仮想サーバーやアプリケーションの反応が鈍くなり、最悪の場合はサーバーにアクセスできなくなります。そのため、このコンポーネントの監視は不可欠です。SNMP CPU Load センサーは、サーバーのプロセッサの負荷を監視し、対策が必要な箇所を示します。
Memory センサー
また、RAM はスムーズな動作を確保するために重要な役割を果たしています。RAM 監視は、お客様のすべてのシステムのメモリを常に監視します。リソースを大量に消費するアプリケーションや負荷の高いサーバーを特定するのに役立ちます。時として、最も単純なアプリケーションであっても大量のメモリを消費し、サーバー全体のパフォーマンスに影響を与えることがあるからです。SNMP Memory センサーは、RAM の状態とシステムのメモリ使用量を監視します。
Physical Disk センサー
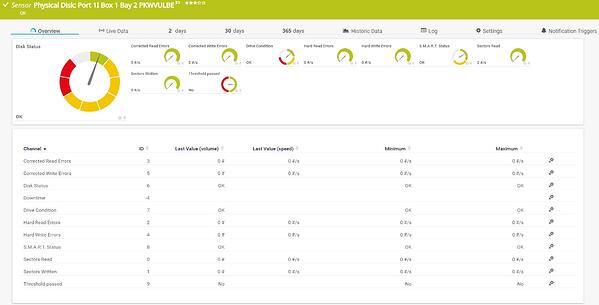
ハードディスクのメモリ使用率に関する情報に加えて、個々の物理的なハードディスクの状態を知ることは非常に重要です。今日では、RAID のおかげで、1 つのディスクの障害は許容され、通常は大きな問題ではありませんが、場合によっては重大な影響を与えることがあります。そのため、個々のハードディスクの状態を監視することをお勧めします。PRTG には、SNMP HPE ProLiant Physical Disk センサー、SNMP Dell PowerEdge Physical Disk センサー、SNMP IBM System X Physical Disk センサーなど、メーカー別のセンサーが多数用意されています。また、ストレージ システム用のセンサーも用意されています。
Logical Disk センサー
個々の物理ディスクを監視するのと同様に、PRTG は論理ディスク (論理ボリュームや仮想ディスクとも呼ばれる) を監視するセンサーを提供します。論理ディスクは、物理ディスクとは異なり、複数の物理ディスクで構成されており、構成によっては、1 つのディスクが故障してもデータの損失を防ぐことができます。SNMP HPE ProLiant Logical Disk センサー、SNMP IBM System X Logical Disk センサー、Dell PowerVault MDi Logical Disk センサーなどのセンサーを使用すると、論理ディスクの使用率だけでなく、ステータスも監視することができます。
Traffic センサー
サーバーの物理的なコンポーネントを監視する以外にも、もちろんデータ トラフィックも無視できません。SNMP Traffic センサーは、ネットワーク カードのポートが接続されているかどうかだけでなく、そこを流れるデータ トラフィックについても通知します。これにより、ネットワークを多用するアクティビティを迅速に特定し、ボトルネックを解消することができます。さらに、センサーからの情報を利用して、ネットワーク トラフィックを最適化することもできます。
System Health センサー
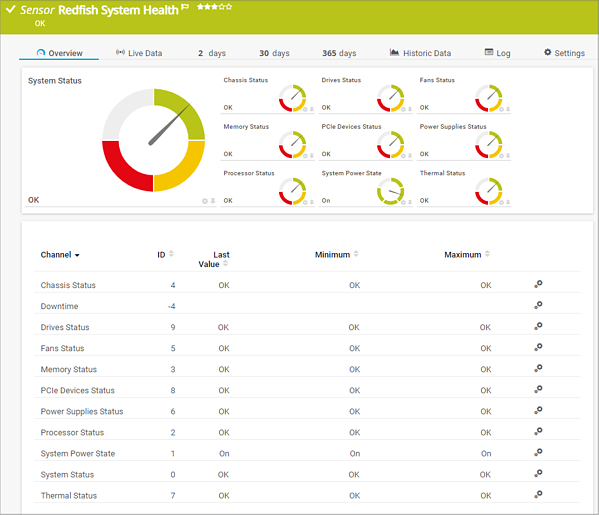
PRTG には、サーバー コンポーネントを監視する個々のネイティブ センサーに加えて、有名メーカーのハードウェア用の System Health センサーが含まれています。これらのセンサーは、例えば、バッテリーの状態、温度、グローバル システムの状態、シャーシの状態などの情報をチャネルで提供します。System Health センサーは、Dell、HPE、IBM などのサーバー ハードウェアだけでなく、NetApp、Buffalo、富士通、Lenovo などのデバイスにも使用することができます。
Redfish センサー
Redfish Scalable Platforms Management API (Redfish) は、REST ベースのソフトウェア インターフェイスを介してサーバー システムのリモート メンテナンスを行うための仕様です。Redfish は標準的なプロトコルであるため、 多くのサーバー ハードウェア ベンダーが使用しています。Redfish System Health Sensor (EXPERIMENTAL) を使用すると、PRTG がこの目的のためのネイティブ センサーを提供していない場合でも、サーバー ハードウェアを監視することができます。このセンサーのチャネルは、ファン、ドライブ、PCIe デバイス、プロセッサなどのステータスを通知します。Redfish System Health Sensor の詳細については、こちら (英語) をご覧ください。
ご覧のように、サーバー ハードウェアの監視に使用できるセンサーは数多くあります。ここで紹介したセンサーは、PRTG に搭載されているセンサーのほんの一部で、すぐに使用することができます。利用可能なすべてのセンサーの概要はこちら (英語) をご覧ください。
私たちが現在取り組んでいる新しいセンサーや、今後取り組む予定のセンサーについて知りたい方は、ロードマップ (英語)をご覧ください。
この資料は、Paessler の Blog で公開されている「Top sensors in PRTG to monitor your Dell, HPE and IBM server hardware」の日本語参考訳です。