進化し続ける AI の世界では、特にプライバシーと安全性における優位性から、ローカル モデルが注目されています。ローカル モデルを使用してチャットボットを開発し、展開する機能は、データの安全性、プライバシー、コスト管理において特に価値があります。Mistral と Llama2 は、オープンソースのローカル大規模言語モデル (LLM) の中で最も優れた性能を持つモデルのうちの 2 つとして挙げられます。
2023 年 7 月に Meta 社から発表された Llama2 は、最先端の LLM コレクションです。70 億個、130 億個、700 億個のパラメーター モデルを提供し、研究、商用利用にはすべて無料で利用できます。Mistral AI が 2023 年 9 月にリリースした Mistral 7B は、そのサイズにおいて最も強力な LLM として認知されています。Llama2 13B よりもパラメーター数が少ないため、より早く、簡単に作業ができるのにもかかわらず、すべてのベンチマークで Llama2 13B を上回っています。
この 2 つの基本モデルと、オープンソース プロジェクトである Panel のチャット インターフェイスを活用し、ローカル モデルで AI チャットボットを作ることがいかに簡単かをご紹介します。
この記事では、以下の方法について説明します。
- Mistral 7B モデルを使用する
- レスポンスのストリーミング処理を追加する
- Panel のチャット インターフェイスを使って Mistral 7B で AI チャットボットを構築する
- Mistral 7B と Llama2 の両方で AI チャットボットを構築する
- LangChain を使って Mistral 7B と Llama2 の両方で AI チャットボットを構築する
作業を始める前に、panel==1.3、ctransformers、langchain をインストールする必要があります。NVIDIA の GPU を使っている場合は、ctransformers[cuda] をインストールしてください。
それでは始めましょう!
Mistral を使い始める
まずは、GGUF 形式に量子化された Mistral 7B Instruct で、`AutoModelForCausalLM` という AutoClass を使ってモデルを読み込んでみましょう。AutoClass は、モデルのパスからモデルを自動的に取得するのに役立ちます。AutoModelForCausalLM は因果言語モデリングを持つモデル クラスの 1 つで、Mistral 7B Instruct モデルに必要なものです。
Python
# Source: https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
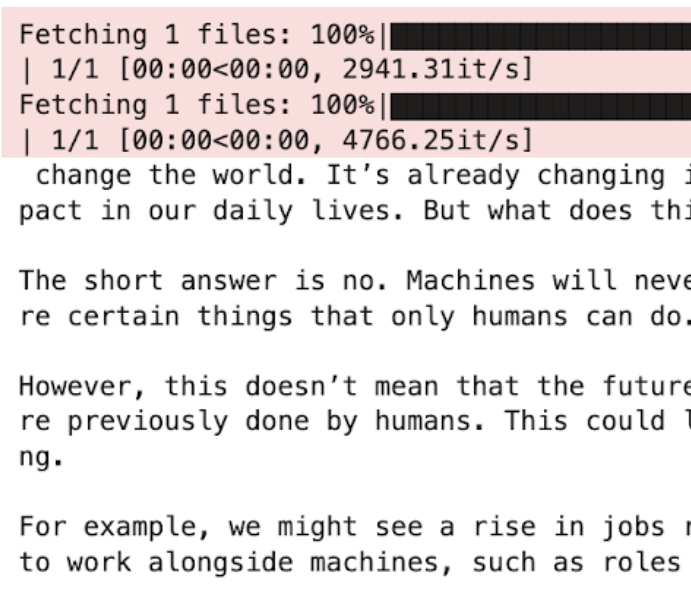
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
レスポンスのストリーミング処理を追加する
上記の例では、モデル推論を実行すると、レスポンス全体が生成されてから 1 つのレスポンスが返されます。これは、長いレスポンスを生成する場合には時間がかかることがあります。また、チャット インターフェイスでは、モデルが 1 つずつ単語を「入力」しているのが見える方が自然かもしれません。そのため、レスポンスの生成中にストリーミングしたくなることがあります。これを行うには、モデルを呼び出す際に `stream=True` を追加します。
モデルのレスポンス速度を上げるために、`async` を使って IO タスクがバックグラウンドで実行されるようにし、モデルのレスポンスを待っている間にコンピューターが他のタスクを実行できるようにします。
Python
from ctransformers import AutoModelForCausalLM
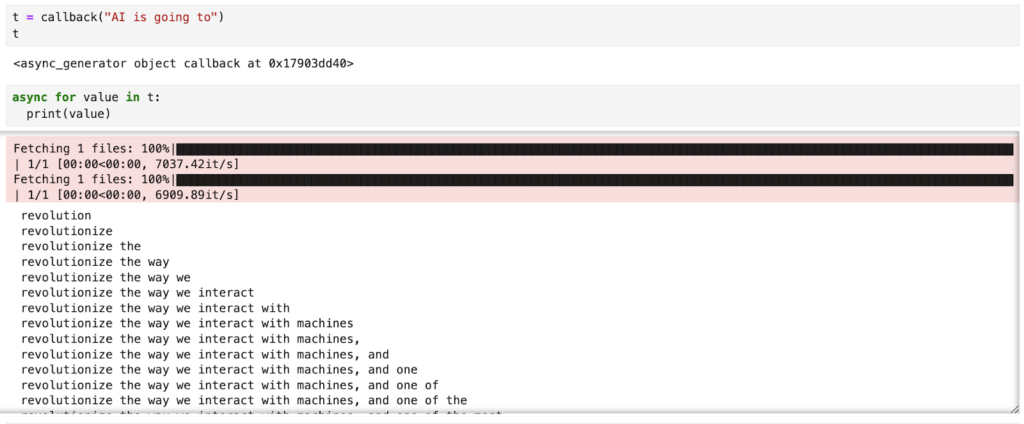
async def callback(contents: str):
llms = {}
if "mistral" not in llms:
llms["mistral"] = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",
gpu_layers=1,
)
llm = llms["mistral"]
response = llm(contents, stream=True, max_new_tokens=1000)
message = ""
for token in response:
message += token
yield message`callback` 関数の結果は非同期ジェネレーターで、非同期に送られてくるデータを繰り返し処理することができます。値を出力してみると、レスポンス トークンが 1 つずつ生成されていく様子がわかります。
Mistral 7B で 1 つ目の AI チャットボットを構築する
このモデルをチャット インターフェイスに組み込むにはどうすればよいでしょうか?Panel を使えば、わずか 5 行のコードでチャットボットを作成できます!
- まず、ChatInterface ウィジェットを定義します。 chat_interface = pn.chat.ChatInterface(callback=callback, callback_user=”Mistral”) このウィジェットは、チャットボットのすべての UI とロジックを処理します。システムがどのように応答するかを `callback` 関数で定義する必要があることに注意してください。
- 「Mistral からの返信を得るには、メッセージを送信してください!」というシステム メッセージでチャットボットをスタートさせ、ユーザーが何をすべきかを明確に指示できるようにしましょう。
- そして最後に、chat_interface.servable() でローカルでもクラウドでもアプリを提供できるようにします。アプリを提供するには、以下のコードをスタンドアロンの Python ファイル (app.py) または Jupyter Notebook ファイル (app.ipynb) として保存し、`panel serve app.py` または `panel serve app.ipynb` を実行します。
注: 非同期コールバックは必須ではありませんが、ユーザー エクスペリエンスの向上につながります。
OpenAI API と LangChain を使って AI チャットボットを構築する方法に興味がある方は、以前のブログ記事 (英語) をご覧ください。
Python
"""
Demonstrates how to use the ChatInterface widget to create a chatbot using
Mistral thru CTransformers.
"""
import panel as pn
from ctransformers import AutoModelForCausalLM
pn.extension()
async def callback(contents: str, user: str, instance: pn.chat.ChatInterface):
if "mistral" not in llms:
instance.placeholder_text = "Downloading model; please wait..."
llms["mistral"] = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",
gpu_layers=1,
)
llm = llms["mistral"]
response = llm(contents, stream=True, max_new_tokens=1000)
message = ""
for token in response:
message += token
yield message
llms = {}
chat_interface = pn.chat.ChatInterface(callback=callback, callback_user="Mistral")
chat_interface.send(
"Send a message to get a reply from Mistral!", user="System", respond=False
)
chat_interface.servable()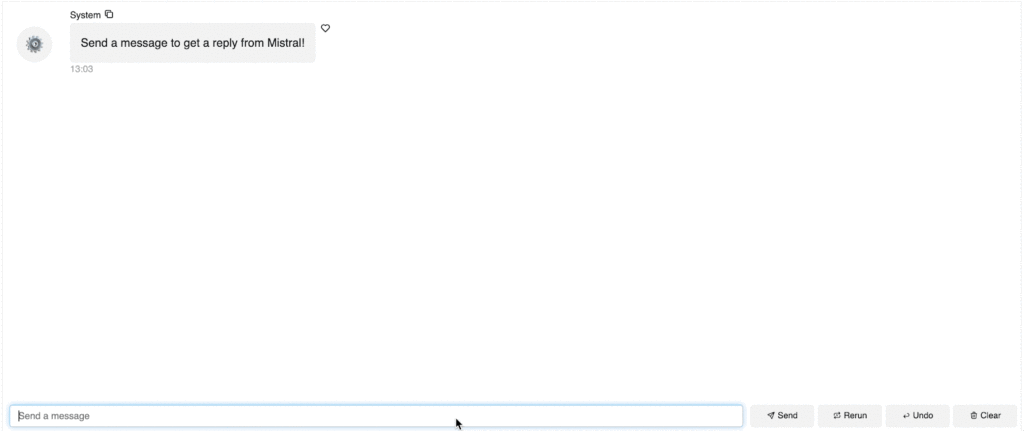
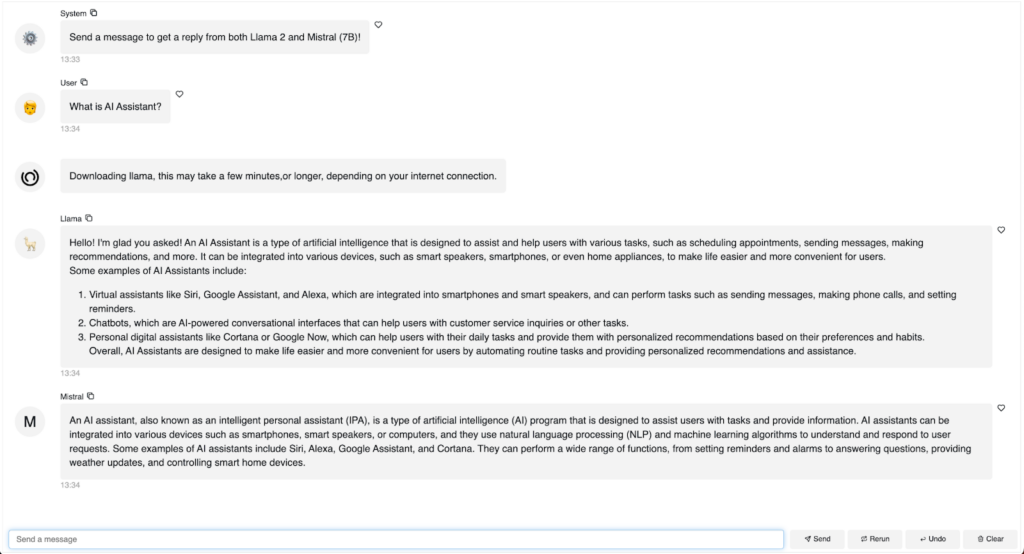
Mistral 7B と Llama2 7B の両方で 2 つ目のチャットボットを構築する
別のモデルからのレスポンスを追加できるでしょうか。異なるモデルからのレスポンスを比較できるでしょうか。はい、もちろん可能です!以下はその例です。
- モデル名、モデルのパス、モデル ファイルなどの情報を MODEL_ARGUMENTS で定義します。
- それから、for ループ で各モデルを別々に渡し、レスポンスをチャット インターフェイスに送ります。
Python
"""
Demonstrates how to use the ChatInterface widget to create a chatbot using
Llama2 and Mistral.
"""
import panel as pn
from ctransformers import AutoModelForCausalLM
pn.extension()
MODEL_ARGUMENTS = {
"llama": {
"args": ["TheBloke/Llama-2-7b-Chat-GGUF"],
"kwargs": {"model_file": "llama-2-7b-chat.Q5_K_M.gguf"},
},
"mistral": {
"args": ["TheBloke/Mistral-7B-Instruct-v0.1-GGUF"],
"kwargs": {"model_file": "mistral-7b-instruct-v0.1.Q4_K_M.gguf"},
},
}
async def callback(contents: str, user: str, instance: pn.chat.ChatInterface):
for model in MODEL_ARGUMENTS:
if model not in pn.state.cache:
pn.state.cache[model] = AutoModelForCausalLM.from_pretrained(
*MODEL_ARGUMENTS[model]["args"],
**MODEL_ARGUMENTS[model]["kwargs"],
gpu_layers=1,
)
llm = pn.state.cache[model]
response = llm(contents, max_new_tokens=512, stream=True)
message = None
for chunk in response:
message = instance.stream(chunk, user=model.title(), message=message)
chat_interface = pn.chat.ChatInterface(callback=callback)
chat_interface.send(
"Send a message to get a reply from both Llama 2 and Mistral (7B)!",
user="System",
respond=False,
)
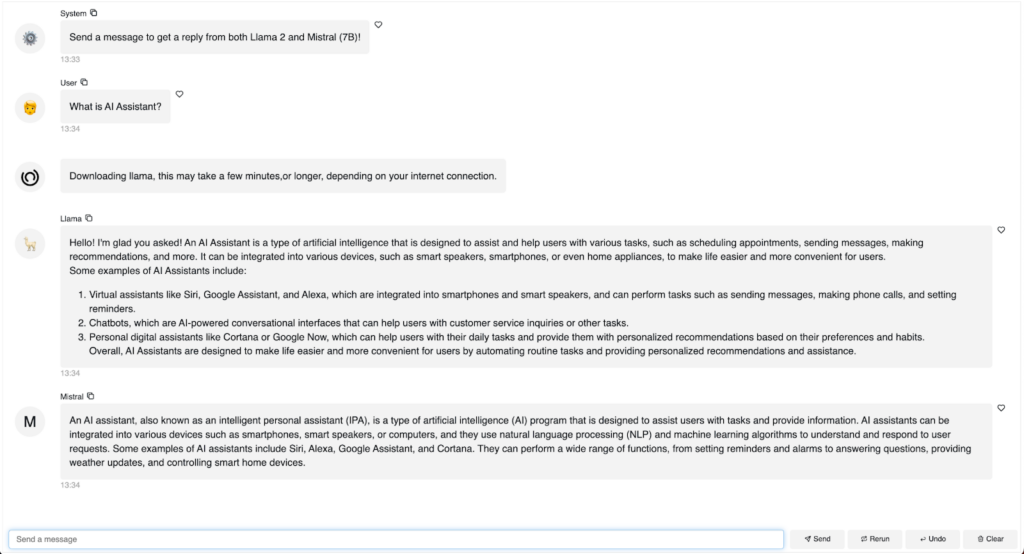
chat_interface.servable()`panel serve app.py` または `panel serve app.ipynb` を実行したら、Llama2 と Mistral の両方とチャットし、そのレスポンスを直接比較することができます。
LangChain を使って Mistral 7B と Llama2 7B で 3 つ目のチャットボットを構築する
LangChainで同様のチャットボットを構築することは可能でしょうか?はい、可能です! LangChain は、多くの人にとって便利な LLM アプリ開発のためのフレームワークです。
- LangChain は CTrasnformers ラッパーを提供しており、langchain.llms import CTransformers でアクセスできます。CTransformers の統一インターフェイスを使って 2 つのモデルを読み込むことができます。
- PromptTemplate は、言語モデルに送信するプロンプトを生成するための、再利用可能なテンプレートを定義するのに役立ちます。 プロンプト変数でプロンプトを定義します。
- LLMChain を使用して、プロンプトを言語モデルと連鎖します。具体的には、与えられた入力値を用いてプロンプト テンプレートをフォーマットし、フォーマットされたプロンプトを言語モデルに渡し、出力を返します。
Python
"""
Demonstrates how to use the ChatInterface widget to create a chatbot using
Llama2 and Mistral.
"""
import panel as pn
from langchain.chains import LLMChain
from langchain.llms import CTransformers
from langchain.prompts import PromptTemplate
pn.extension()
MODEL_KWARGS = {
"llama": {
"model": "TheBloke/Llama-2-7b-Chat-GGUF",
"model_file": "llama-2-7b-chat.Q5_K_M.gguf",
},
"mistral": {
"model": "TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
"model_file": "mistral-7b-instruct-v0.1.Q4_K_M.gguf",
},
}
llm_chains = {}
TEMPLATE = """<s>[INST] You are a friendly chat bot who's willing to help answer the user:
{user_input} [/INST] </s>
"""
async def callback(contents: str, user: str, instance: pn.chat.ChatInterface):
config = {"max_new_tokens": 256, "temperature": 0.5}
for model in MODEL_KWARGS:
if model not in llm_chains:
instance.placeholder_text = (
f"Downloading {model}, this may take a few minutes,"
f"or longer, depending on your internet connection."
)
llm = CTransformers(**MODEL_KWARGS[model], config=config)
prompt = PromptTemplate(template=TEMPLATE, input_variables=["user_input"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
llm_chains[model] = llm_chain
instance.send(
await llm_chains[model].apredict(user_input=contents),
user=model.title(),
respond=False,
)
chat_interface = pn.chat.ChatInterface(callback=callback, placeholder_threshold=0.1)
chat_interface.send(
"Send a message to get a reply from both Llama 2 and Mistral (7B)!",
user="System",
respond=False,
)
chat_interface.servable()`panel serve app.py` または `panel serve app.ipynb` を実行すると、LangChain を使用して Llama2 と Mistral の両方のモデルで交信するチャットボットが表示されます!
おわりに
このブログ記事では、Mistral 7B のインストラクト モデルを実行する方法、レスポンスのストリーミング処理と非同期ジェネレーターを使用してパフォーマンスを向上させる方法、Panel のチャット インターフェイス ウィジェットを使用してチャットボットを構築する方法、Mistral 7B と Llama2 7B の両方を使用してチャットボットを構築する方法、そして最後に LangChain を使用してチャットボットを構築する方法を紹介しました。この記事に価値を見出していただければ幸いです。Happy coding!
注: この記事で見られるコードは、以下にて入手可能です。
これらのツールはすべてオープンソースで、誰もが無料で使うことができますが、データサイエンス、機械学習、AI 向け Python/R プラットフォームの Anaconda についてはこちらをご参照ください。
2024 © Anaconda Inc.
「How to Build AI Chatbots with Mistral and Llama2」
