
現在、ML の運用者、データ サイエンティスト、開発者は、大きなセキュリティ課題に直面しています。まず、攻撃手法の進化に対応するには、常に警戒しながらセキュリティの知識を身につける必要がありますが、それを徹底するには専任のセキュリティ チームが不可欠です。さらに、現在の ML モデルのスキャン エンジンは、誤検知が非常に多いという問題を抱えています。
安全なモデルが誤って危険と判断されると、不必要なアラートが発生し、システムが混乱しやすくなります。その結果、チームは実際の脅威への感度が鈍り、MLOps やセキュリティ チームはノイズに埋もれてしまいます。これにより、アラートの重要性が薄れ、本当に対処すべき脅威を見逃すリスクが高まります。さらに深刻なのは、危険なモデルが検出されずにすり抜ける「偽陰性」の問題です。これが発生すると、ML の実践者は攻撃を受けたことすら認識できず、より重大なリスクにつながります。
偽陽性と偽陰性は、AI/ML モデルのセキュリティ確保において大きな課題となります。偽陽性 (誤検知) は、安全なモデルを誤って脅威と判断し、リソースを無駄にするだけでなく、アラート疲弊を引き起こします。一方、偽陰性 (見逃し) は、実際の脆弱性を検出できず、システムを危険にさらします。これらの誤判定が重なることで、ワークフローが混乱し、セキュリティ対策への信頼も損なわれてしまいます。
JFrog は、これらの差し迫った課題を認識し、ML モデルのセキュリティを再定義することで AI/ML 開発を加速する機会を見出しました。Hugging Face との統合により、同プラットフォームのスキャナーが検出する誤検知の 96% を排除すると同時に、従来のスキャナーでは見逃されていた脅威を特定する、強力な方法論主導のアプローチを実現します。この革新的な技術により、ノイズを排除し、利害関係者に信頼できる明確な指標を提供する真のセキュリティ インサイトを確保します。
JFrog は現在、組み込みの「ファイル セキュリティ スキャン」インターフェースを活用し、Hugging Face でホストされているすべての ML モデルに対して悪意のあるモデルのスキャンを提供しています。
この次世代のセキュリティ統合により、MLOps のあり方が大きく変わり、AI モデルのセキュリティがより正確で分かりやすくなります。
JFrog Hugging Face の悪意あるモデル スキャン
Hugging Face の事前トレーニング済みモデルは、AI イノベーションの最前線にありますが、過去の調査で示したとおり、セキュリティ上の課題も抱えています。実際、攻撃者はすでにこれらのモデルにバックドアを仕掛けようとしています。
これらのリスクを軽減するために、Hugging Face は Microsoft と共同でオープンソースのモデル スキャナー「Picklescan」を開発し、シリアル化されたモデル データを精査して潜在的な脅威を検出しています。さらに、Protect AI などの商用スキャナーがプラットフォームに統合され、モデルの安全性をさらに評価されています。しかし、これらのセキュリティ レイヤーにもかかわらず、システムは依然として大量の誤検知を生成しており、その結果、アラートの有効性が低下し、実際の脆弱性が見逃される可能性があります。
現在のスキャナーは貴重な洞察を提供しますが、本物の脅威と誤検知を区別するために必要な明確さを欠いています。そこで、JFrog の統合が効果を発揮します。強化されたセキュリティ インジケーターは、モデル ファイルとそれに関連する構成ファイル (危険なペイロードが潜んでいる可能性がある) を精査するだけでなく、万が一潜在的な脅威が誤検知として却下された場合でも、JFrog の新しい「モデル脅威」ウェブサイトで明確かつ詳細な説明を提供します。

JFrog のモデル スキャナーで検出された攻撃の種類
事前トレーニング済みのモデルは、AI アプリケーションで広く利用されており、開発者は大規模なトレーニングを必要とせずに既存のアーキテクチャを活用できます。一般的なワークフローでは、モデルをメモリにロードし、それを使用して新しいデータに対して予測を行います (これは一般的に「推論」または「クエリ」とも呼ばれます)。一見簡単なプロセスに思えますが、この両方の段階で重大なセキュリティ リスクが存在します。
モデルがロードされると、逆シリアル化し初期化が行われます。このプロセスでは、ファイル形式に応じて埋め込まれたコードが実行される可能性があります。その後、予測の際にモデルは入力データを処理して出力を生成しますが、ここでもモデルが改ざんされている場合、悪意のあるコードがトリガーされるリスクがあります。よく知られた汚染されたデータ セットのリスクに加えて、もう一つの重大な脅威は、事前トレーニング済みモデル内に隠されたバックドアの存在です。これらのバックドアは、特定のトリガー入力に対してハードコードされた出力を返すように設計されており、攻撃者はターゲットを絞り、検出されることなく予測を操作することができます。
さまざまなモデル形式が異なる方法でこれらの段階を処理し、それに伴ってセキュリティ リスクも変わります。JFrog のモデル スキャナーが検出を試みる攻撃の種類は以下の通りです。
- Pickle ベースのモデル (PyTorch、Joblib、NumPy、Dill など) では、ロード時にコードの実行が許可されます。つまり、悪意のあるユーザーがモデルを開くと、その時点で実行される有害なコードを埋め込むことができます。
- TensorFlow モデル (H5、Keras、SavedModel など) は、モデルの構造に応じて、ロード時または予測中に任意のコードを実行することができます。
- GGUF モデルは、特に予測段階でコードを実行することができ、攻撃者は推論中に有害な操作を行うペイロードを作成することが可能です。
- ONNX モデルは一般的により安全であると考えられていますが、予測中にアクティブになるアーキテクチャ上のバックドアが存在する可能性があり、これによって機密データが漏洩したり、結果が操作されたりするリスクがあります。
- 他のモデルタイプも、ロードまたはクエリ時にコード実行のリスクを伴う可能性があります。サポートされているモデルの完全なリストについては、ドキュメントをご確認ください。
これらのセキュリティ脅威は単なる理論的なものではなく、攻撃者はすでに侵害されたモデルを利用して不正なアクションを実行する方法を実証しています。これらのリスクを理解することで、JFrog の統合が提供するプロアクティブな保護が確保され、読み込み段階と予測段階の両方で脅威を特定し、AI アプリケーションを保護することができます。
さまざまなモデル タイプに関連するセキュリティ リスクをより深く理解するために、モデルを攻撃対象領域に基づいて分類し、それぞれの潜在的な脆弱性を詳述する専用の「モデルの脅威」Webページを用意しました。これらのリソースは、Pickle、TensorFlow、GGUF、ONNX などのさまざまな形式がどのように悪用される可能性があるか、また、事前トレーニング済みモデルをワークフローに統合する際にユーザーが認識しておくべき特定の脅威についての洞察を提供します。
これらの課題に対応するために、JFrog は検出にとどまらず、排除された脅威と確認された脅威の両方について明確で実用的なエビデンスを提供します。JFrog のセキュリティ インジケーターは、潜在的な問題を警告するだけでなく、モデルに埋め込まれた逆コンパイルされた悪意のあるコードを表示するなど、モデルやファイルが安全または危険であると判断された理由を説明します。さらに、JFrog は安全なプロキシである JFrog Curation を提供し、高リスクと特定されたモデルのダウンロードを積極的にブロックすることで、検証済みの信頼できる AI モデルのみが環境に侵入できるようにします。
JFrog の画期的なモデル スキャン技術
JFrog のスキャン方法論は、まさにゲームチェンジャーです。信頼できるソース アプローチを確立することで、一般的な ML モデル、特に Hugging Face モデルに対するセキュリティ分析の実行方法を再定義しています。
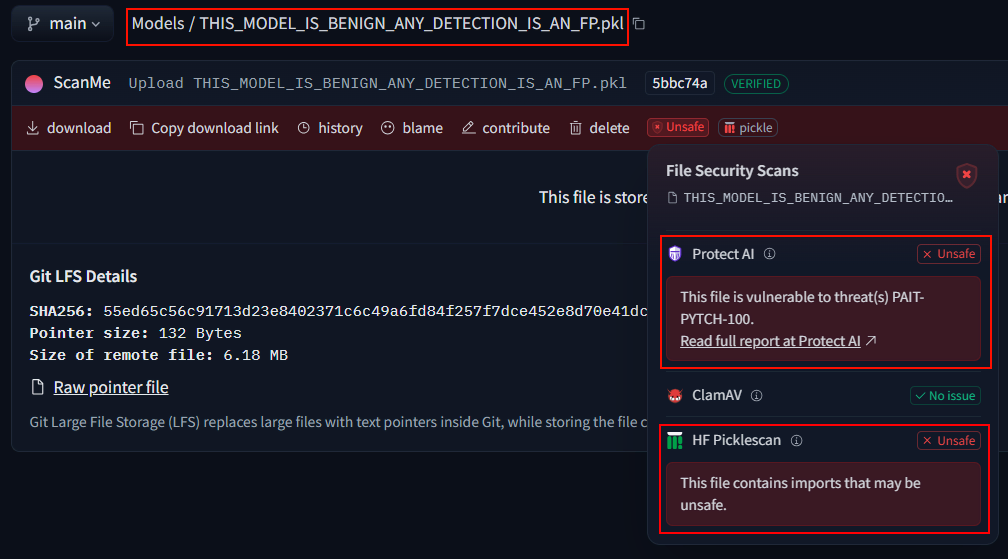
具体的な例を見てみましょう。JFrog が注目した「安全でない」とマークされたモデルの 1 つには、非常に分かりやすいファイル名 (THIS_MODEL_IS_BENIGN_ANY_DETECTION_IS_AN_FP.pkl) が付けられています。これは未知のサードパーティによってアップロードされたモデルで、その名前の通り、実際には危険ではなく、無害なテスト モデルにすぎません。しかし、Hugging Face に統合されている現在の関連スキャナーによって安全でないとフラグが付けられています。
誤検知となる理由は?
問題は、現在のスキャナーが Pickle ベースのモデルを分析する方法にあります。スキャナーは実行ロジックを詳細に調べるのではなく、主に静的分析を行い、Pickle ファイル内でインポートされているモジュールや関数呼び出しをチェックします。特に悪意のある動作に関連していることが多い関数 (例えば getattr など) が検出されると、モデルは自動的に「安全でない」とマークされます。しかし、この方法には根本的な問題があります。getattr 自体は必ずしも危険なわけではなく、その使用方法によって異なります。実際、fastai などの多くの正当な ML ライブラリは、ML モデルをトレーニングする際に正当な理由で getattr を使用しており、このような単純な検出方法では誤検知が多くなりがちです。
def process_data(user_input):
dangerous_func = getattr(os, 'system')
dangerous_func(f'echo Processing {user_input}')
user_controlled_input = "data; rm -rf ~/*"
process_data(user_controlled_input)想像しているよりも大きな問題である可能性は
これが孤立したケースであれば、それほど大きな問題にはならないかもしれません。しかし、現実はそれよりもはるかに深刻です。Pickle スキャンによって「安全でない」とフラグが付けられた Hugging Face のすべてのモデルを分析した結果、驚くべき統計が明らかになりました。なんと、96% 以上が誤検知でした。これらの多くは、前述の getattr の簡略化によって発生しましたが、すべてがそうではないことも分かりました。
JFrog の調査は Pickle ベースのモデルだけに焦点を当てたものではなく、TensorFlow モデルも分析しましたが、その結果はさらに憂慮すべきものでした。今回は、誤検知だけでなく、多くの見逃された脅威も発見しました。つまり、実際の脅威が検出されなかったということです。
TensorFlow モデルにおける最も重要な攻撃ベクトルの 1 つは、Lambda レイヤーです。このレイヤーにより、ユーザーはモデル内で任意の Python コードを実行できるため、悪意のあるペイロードの潜在的なゲートウェイとなります。事前トレーニング済みモデルに存在する場合、Lambda レイヤーは base64 でエンコードされ、コンパイルされた Python バイトコードとして保存されるため、従来の静的スキャン手法では分析が非常に困難になります。
現在のセキュリティ ツールは、Lambda レイヤーを含むモデルを単に「疑わしい」とフラグ付けするだけで、それ以上の詳細な検査を行わない傾向があります。しかし、これにはいくつかの問題があります。
- すべての Lambda レイヤーが悪意のあるわけではない。多くのモデルでは、パフォーマンスや柔軟性を向上させるために正当に使用されています。そのため、セキュリティ スキャナーは大量の不要なアラートを生成することになります。
- 「疑わしい」とマークされているモデルが多すぎる。現在、Hugging Face では、広く使用されている正当なモデルを含む 28,000 以上のモデルが「疑わしい」とマークされています。これにより、ML ユーザーは「疑わしい」というラベルを完全に無視してしまうことになります。
- 本当に悪意のあるモデルは、従来のスキャナーでは検出されない Lambda レイヤー難読化技術を使用して、検出を完全に回避します。
誤検知がユーザーを圧倒し、誤検知が実際の脅威を見逃してしまう状況では、既存のセキュリティ対策が不十分であることは明らかです。そのため、JFrog はこれらのモデルを効果的に保護するための新しい異なるアプローチの開発に着手しました。
JFrog エビデンス エンジンの方法論
上記の調査結果に基づき、JFrog は誤検知を大幅に削減し、かつお客様に完全な透明性を提供する、ML モデルの高度なスキャン方法を開発しました。
従来のセキュリティ アプローチの多くは、埋め込まれたコードを識別することにとどまっています。これは、モデルが危険かどうかを判断するための一般的な方法です。しかし、この手法では、埋め込まれたコードが存在するかどうかはわかりますが、それが実際に脅威をもたらすものなのか、単に無害な実装の一部なのかを正確に判断することはできません。もっと詳しく調べなければ、そのコードが悪意のあるものであるかどうかを区別することは難しいのです。
JFrog のアプローチはさらに進んでいます。埋め込みコードを識別した後、実際の脅威と誤検知を分けるために、さらに高度なフィルタリングを行います。まず、埋め込まれたコードを抽出し、逆コンパイルして、単純な機能チェック以上の詳細な分析を実施します。次に、エビデンス抽出プロセスでペイロードを正規化された形に変換し、単なるキーワードによるフラグ付けではなく、コンテキストを考慮した分析をします。これにより、GetAttr などの関数が正当な目的で使われているのか、悪意のある目的で使われているのかを的確に判断できます。
最後に、必要なエビデンスがすべて揃った段階で、誤検知を排除し、無害なモデルが誤ってフラグ付けされることがないようにします。その上で、実際にセキュリティリスクをもたらすモデルのみを残します。
この方法論を採用することで、JFrog は誤検知を減らすだけでなく、脅威の範囲を明確にし、完全な透明性を提供します。詳細でエビデンスに基づいたセキュリティ評価を受けることができ、過剰なノイズに惑わされることなく、結果を信頼できるようになります。これにより、セキュリティが強化されるだけでなく、使いやすさも向上し、実際の脅威に適切に対応できるようになります。
ケース スタディ 1: GetAttr の例 — 誤検知
先ほど説明した GetAttr の例を、THIS_MODEL_IS_BENIGN_ANY_DETECTION_IS_AN_FP.pkl モデルを使って再度見てみましょう。以下は、既存のスキャナーがこのモデルを「安全でない」とフラグ付けした原因となった抽出エビデンスです。
[{"code":"_var7814 = getattr(Detect,
'forward')","reason":"getattr","line_no":8627,"scanner_type":"dangerous_imports"}]この結果は、GetAttr 関数を潜在的なセキュリティ リスクとして自動的にフラグ付けする標準的な「危険なインポート」スキャンによるものです。しかし、この場合、それが本当に危険だとは言えません。
GetAttr は機械学習モデルのどこに正しく表示されるか
多くのディープラーニング フレームワーク、特にオブジェクト検出モデルでは、GetAttr 関数がモデル定義で頻繁に使用されます。これは、名前に基づいてメソッドや属性を動的に取得し、実行の柔軟性を高めるためです。
例えば、YOLO (You Only Look Once) オブジェクト検出モデルでは、Detect クラスに画像処理のための複数のメソッドが含まれています。行_var7814 = getattr(Detect, 'forward') は、ニューラル ネットワークの標準的な推論操作である forward 関数を取得するためのものです。
なぜこれが誤検知なのか
この例は、いくつかの理由から誤検知であると考えられます。
- 正当な使用例。GetAttr は、モジュール式および動的モデル実行のための ML フレームワークで広く使用されています。
- 悪意のある動作がない。この特定の例では、モデル内の関数を参照しているだけで、外部ソースから任意のコードを実行しているわけではありません。
- 通常のパターン マッチング検出。標準スキャナーは、GetAttr が存在するという理由だけでこのモデルにフラグを立てましたが、その使用方法までは分析していませんでした。
これは、従来のスキャンツールが失敗する理由を示す完璧な例です。従来のスキャンツールでは、特定の機能が存在するだけでそれをすべて危険だと見なしてしまい、誤検知が発生し、ユーザーに大量の警告が届くことになります。
JFrog の高度な方法論では、単純なフラグ付けにとどまらず、抽出されたエビデンスのコンテキストを分析します。すべての GetAttr 呼び出しを盲目的に安全でないとマークするのではなく、システムがそれらの使用方法を調べ、このような無害なモデルが誤って脅威として分類されないようにします。
ケース スタディ 2: 推移的な悪意 – 偽陰性
誤検知はノイズとフラストレーションを引き起こしますが、実際に危険なのは誤検知ではなく、本当の脅威を見逃すことです。その一例が、以下の Hugging Face の zpbrent/transfo-xl モデルです。このモデルは重大なセキュリティリスクを含んでいるにもかかわらず、誤って安全とマークされています。
このケースで抽出されたエビデンスは次のとおりです。
[{"code":"_var0 = getattribute_from_module(AutoTokenizer,
'from_pretrained')","reason":"getattribute_from_module","line_no":
3,"scanner_type":"dangerous_imports"}]これが危険な理由
重要な問題は、transformers.models.auto.auto_factory ライブラリの関数 getattribute_from_module にあります。前述の GetAttr のような単純な属性取得とは異なり、この関数は事前トレーニング済みモデル内のモデルを動的に読み込むことができるため、さらに複雑なセキュリティ リスクを引き起こす可能性があります。
この場合、一見「安全」なモデル zpbrent/transfo-xl は、実際には悪意のあるモデル zpbrent/reuse をダウンロードしてロードしようとしているのです。このような動的読み込みのプロセスは、従来のスキャナーによって検出されることなく行われるため、非常に危険です。
なぜこれが誤検知なのか
これは、モデルの所有者がユーザーに気付かれることなく、またはユーザーからの追加の入力なしに外部モデルをロードできるため、深刻な脅威となります。この仕組みが悪用されると、危険なペイロードやバックドア、さらには任意のコード実行を含む悪意のあるモデルが実行時にロードされる可能性が生じます。
既存のセキュリティ スキャンは、主に基本的なインポートや関数呼び出しのチェックに依存しているため、この脅威を見逃してしまいました。getattribute_from_module 自体は一見悪意があるようには見えませんが、その実際の影響は使用方法によって大きく異なります。
JFrog のセキュリティ階層化によりこの攻撃を阻止した方法
幸いなことに、JFrog の Catalog Proxy は追加のセキュリティ レイヤーとして機能し、この攻撃は標準のスキャナーでは危険とフラグ付けされなくても、JFrog によってブロックされるはずです。
セキュリティは、単一の障害点に依存すべきではありません。2 つの保護層を持つ方が、1 つだけよりも確実に優れています。最初の層は、JFrog の高度な方法論を活用した静的スキャンで、この悪意のあるインポートを検出します。2 番目の層は、JFrog Curation によって、一見安全に見える zpbrent/transfo-xl がダウンロードしようとする実際のペイロード モデル、zpbrent/reuse をブロックします。
ケース スタディ 3: 悪意のあるラムダ層の不十分な分析 – 偽陰性
もう 1 つの危険な誤検知として、Hugging Face の MustEr/vgg16_light モデルを挙げることができます。このモデルは明らかに悪意があるにもかかわらず、単に「疑わしい」とマークされただけでした。これは、ユーザーに対して明確なセキュリティ評価を提供しない、漠然とした分類です。
このケースで抽出されたエビデンスは次のとおりです。
[{"code":"os.system('calc.exe')","reason":"os","line_no":5,"scanne
r_type":"dangerous_imports"}]なぜこれが誤検知なのか
この行は、os.system() 関数を使用してWindowsの電卓 (calc.exe) を実行しています。一見無害に見えるこのコマンドですが、実際にはモデル内で任意のコマンド実行が可能であることを示しています。攻撃者は、この calc.exe を、ユーザーのシステムにマルウェアをダウンロードして実行するためのコマンドに簡単に置き換えることができます。
このモデルがすぐに危険だとフラグ付けされなかった理由は、従来のスキャナーが Lambda レイヤーの存在を検出することにのみ焦点を当てているためです。Lambda レイヤーが見つかると、Lambda レイヤー内のコードに関係なく、モデルは「疑わしい」とマークされます。しかし、すべての Lambda レイヤーが悪意があるわけではなく、また、Lambda レイヤー内の悪意のあるコードがすべて検出されるわけでもないため、このアプローチには問題があります。
前述のように、既存のスキャナーによって「疑わしい」とマークされたモデルが大量に存在するため、AI/ML 開発の専門家は、たとえ重大なセキュリティ リスクを含んでいても、これらのモデルを安全だと見なして扱ってしまう可能性があります。
しかし JFrog の革新的な方法論により、スキャナーは詳細なデコード、逆コンパイル、コード分析を実行し、どのモデルが単に疑わしいだけでなく、本当に安全でないのかを判断できるようになります。
JFrog プラットフォームとは
Hugging Face との統合により、ML プロフェッショナルは使いやすく、より正確なモデルスキャン機能を利用できるようになりますが、JFrog Catalog の機能を統合することで、Hugging Face インターフェースだけでは得られない、各モデルの悪意のあるエビデンスとして使用される逆コンパイルされたコードなど、さらに多くの詳細情報が提供されます。
JFrog Platform の一部である JFrog Catalog の無料トライアルにサインアップして、確認することができます。
まとめ
JFrog の高度なモデル スキャナーを Hugging Face に統合することで、プラットフォームでスキャンされるモデルの徹底性、深度、分類精度が大幅に向上します。既存のスキャナーと比較して、誤検知を 96% 削減した JFrog は、AI/ML 開発チームが誤解を招くアラートを避け、実際の脅威と無害なノイズを正確に区別するのに役立ちます。
JFrog は、従来の静的な指標に頼ることなく、エビデンスに基づいた正確なセキュリティ評価を提供し、ML モデルのセキュリティ スキャンの新たなアプローチを提案しています。JFrog 独自の手法では、埋め込まれたコードを分析し、ペイロードを抽出してエビデンスを正規化することで、誤検知を排除し、より深刻な脅威を検出します。
JFrog のセキュリティ プラットフォームは、単なる検出にとどまらず、真の防御層として機能します。モデルがフラグ付けされた理由を詳しく示し、必要に応じて危険なモデルを完全にブロックします。最先端の分析と新しい AI 攻撃手法の継続的な更新を活用したこの多層的アプローチにより、AI/ML 開発者は誤報に悩まされることなく、進化する脅威に先手を打つことができます。
この統合により、Hugging Face ユーザーは、表示されるデータが正確であり、JFrog の業界をリードするセキュリティ研究に基づいていることを理解することで、モデルのセキュリティに対する信頼が一層高まります。
JFrog Platform に関するご質問は、JFrog 日本正規代理店のエクセルソフトまでお問い合わせください。
記事参照: JFrog and Hugging Face Join Forces to Expose Malicious ML Models
世界の人気ソフトウェアを提供するエクセルソフトのメールニュース登録はこちらから。
